はじめに
こんにちは!ひらちんです!
WEBブラウザの自動操作でおなじみの”Selenium”について、要素の指定をするときに便利なXPathの基本的な使い方を紹介します!
最近のWEBアプリは、テスト・テストでHTMLが変わってしまうなんてことも頻繁にあります。
後で修正しないといけないことを前提に考えると、サクサク直せるXPathが強力な相棒だと思います!
Seleniumって何?ってかたは、まずはこちらをどうぞ!
他にも本文下に、Seleniumに関連する記事を一覧にしています。
XPathとは
XPath(XML Path Language)は、ツリー構造となっているXML/HTMLドキュメントから要素や属性などを指定するための決まった書き方(構文)です。
以前次の記事で、Seleniumで操作したいHTMLの各要素を、それぞれClass・id・Name・Tag・CSSのSelecterで指定する方法を紹介しました。
【EXCEL VBA | ノート】WEBブラウザを自動操作する!Selenium Basicの使い方!その1(Chrome編)
FindElementByClass(***Class名***) FindElementById(***Id名***)
とか みたいなやつですね。
操作対象となる、ボタンや入力ボックスを取得して、その取得したボタンや入力ボックスに対して、クリックしたり、テキストを入力したりしました。
XPathも同じく、要素を指定するときにHTMLのどの部分かを表現するために使えます。
FindElementByXpath(***XPATH***)
あるいは要素が複数の場合は
FindElementsByXpath(***XPATH***)
※(***XPATH***)の部分には、これから説明するXPathの表記を入れる
と書きます。
XPathを使うメリット
XPathを使うことのメリットは以下です
1.記述が分かりやすく柔軟性が高いので、要素指定の正確性やメンテナンス性が高い
XPathは”覚えてしまえば”そもそもの記述が、HTMLの構造を表しているので、後で見返したときもどこの要素を指定しているのか直ぐに分かります。
また、構造のどこを表しているのかというための構文のため、要素指定の柔軟性が高いです。
これまで指定しにくかった要素も、いとも簡単に指定することが出来ます。
2.Chromeなどのブラウザのデベロッパーツールで指定したい要素のXPathを簡単に取得できる
Chromeブラウザなどのデベロッパーツール(F12押したら出てくるやつ)では、目的の要素のXPathを簡単に取得できる機能がついています。CSSセレクターなども取得できるやつですね。
もちろん、ツールで取得した場合のものは柔軟性に欠ける場合が多いので、覚えてしまうとあまり使わないかもしれません。
デベロッパーツールでは、自分で作成したXPathが、ちゃんと目的の要素を指定出来ているかどうかも確認できます。
3.ClassもidもNameもTagも、更には属性値やテキストなどの指定もXPathだけで指定できる
ClassやIdで指定する、FindElementByClass や FindElementById などは、指定の方法を変えるためにメソッド側を変更する必要があります。
XPathは、どうやって要素を指定するかは、XPath側の表記に委ねられますので、とにかくメソッドは”FindElementByXPath”(複数:FindElementsByXPath) 一択です(^o^)
余計なことを考えなくて良くていいですね!
XPathの使い方の基本
まずは、HTMLの構造を理解する
XPathを使うのにまず初めに大事なのは、HTMLの構造を理解することです。
XPathは、HTMLのツリー構造を「/」をで区切りながら表記して表していきます。
例えば次のようなHTMLがあったとします。
<html>
<title>ひらちんの部屋</title>
<body>
<div>
<h1>ひらちんの部屋サンプルHTML</h1>
<div>なんか色々</div>
<table>
<h3>サンプルの表</h3>
<thead>
<tr>
<th>見出し1</th>
<th>見出し2</th>
</tr>
</thead>
<tbody>
<tr>
<td>
<span>1行目data1</span>
</td>
<td>
<span>1行目data2</span>
</td>
</tr>
<tr>
<td>
<span>2行目data1</span>
</td>
<td>
<span>2行目data2</span>
</td>
</tr>
</tbody>
</table>
</div>
</body>
</html>
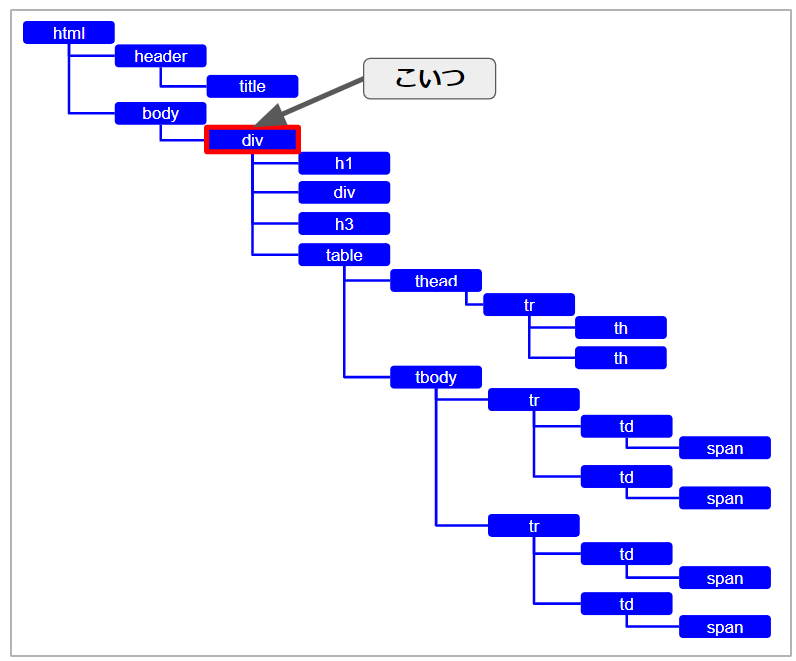
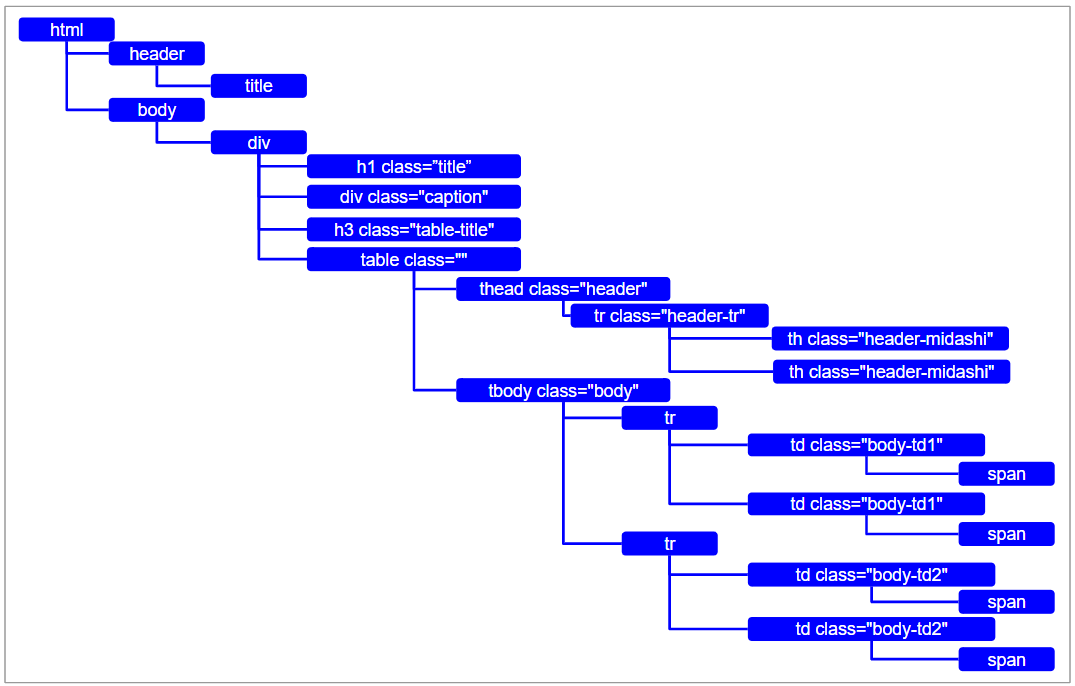
このHTMLタグの構造をもう少し単純化すると次の図のようになっています。
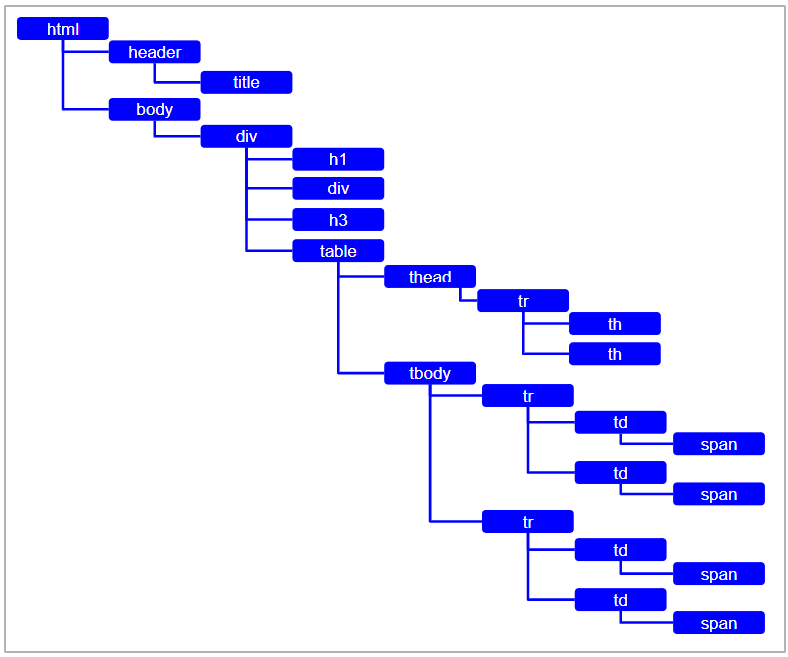
「html」タグを頭に、他のタグがぶら下がっている状態に表現出来ます。
ちょうど、PCで言うフォルダの階層のように、図で言うところの右にいくにつれて階層が深くなっていく構造ですね。
XPathの書き方
XPathは、基本的には、この階層を「 / 」スラッシュ記号でつなげて表していく表記の方法になります。
例えばやってみましょう。
XPathを試すときには、ブラウザに搭載されているデベロッパーツールが便利です。
Chromeブラウザの場合は「F12」キーを押すと出てきます。
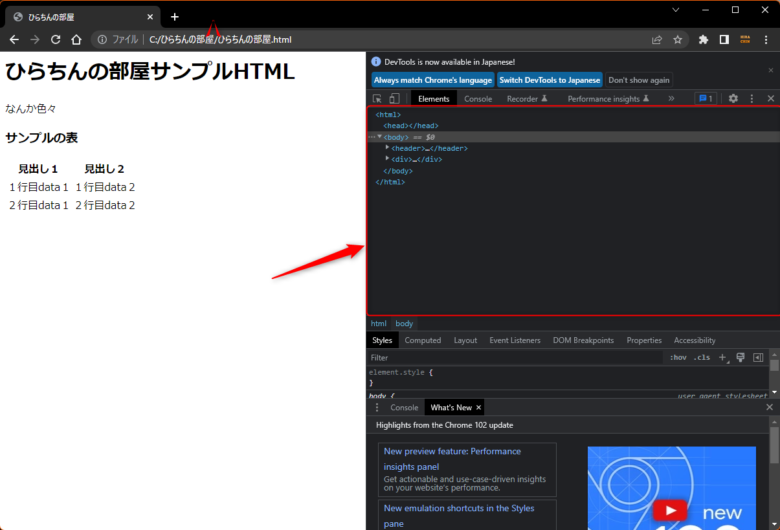
赤枠の中でマウスカーソルをクリックしてから「Ctrl + F」を押すと
次の図のような検索ボックスが出てきます。
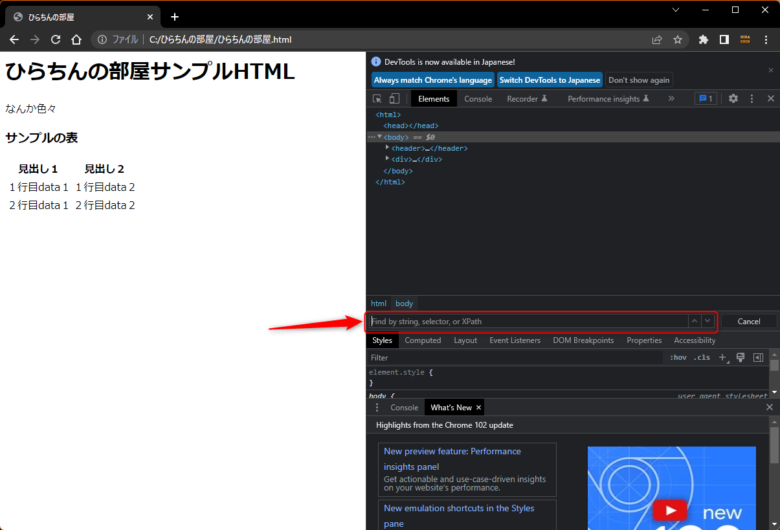
このボックスの中に、XPathを入力すると、XPathがヒットすれば、該当の要素がハイライトで表示されます。
試しに、最初に出てくる「div」タブを指定してみましょう。
XPathでは次のように表記します。
/html/body/div
デベロッパーツールの検索ボックスに入れてみましょう。

ヒットしている要素がハイライトされているのが分かりますね(^o^)
検索ボックスの右側に出てくる「1 of 1」というのは、現在ハイライトされている要素が、何個ヒット中の何番目かを示しています。
図では、「1 of 1」なので、1個中の1番目がハイライトされているよ~ということですね。
/html/body/div
は、次の図の赤枠で示すように、「html」タグから取得したい要素までを順番に、階層を降りていった時、その間にある要素(ここではタグ)を「/」記号でつなげて書いているだけです。
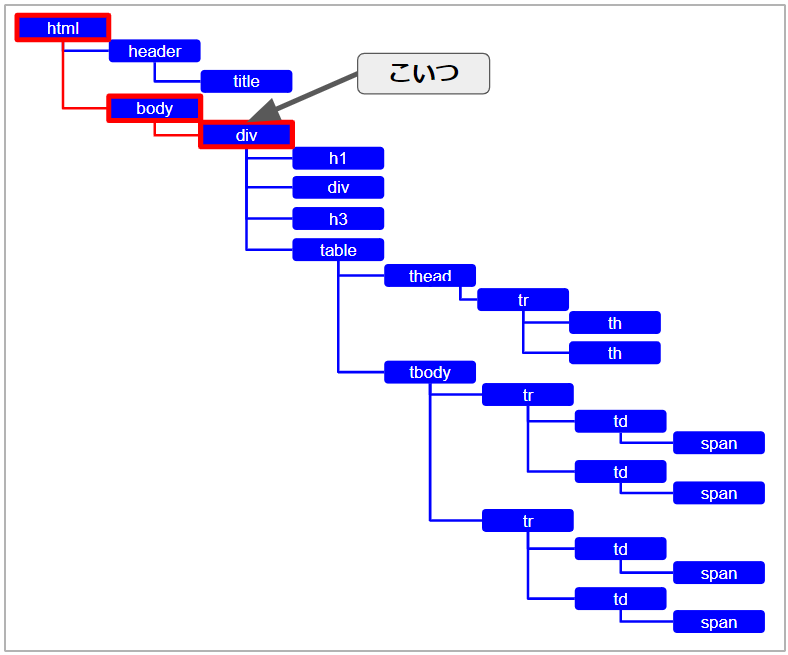
簡単ですね(^o^)
Seleniumで表記する場合は、このXPathをコピペして、
FindElementByXpath(“/html/body/div”)
このように書くことで、目的だった「div」タグが取得できることになります。
複数の要素を取得する
同じ階層に同じXPathでヒットする要素が複数あると、「1 of 2」などで表示されます。
例えば、次の図の tbodyタグの次のtrタグはそうですね。

XPathで
/html/body/div/table/tbody/tr
とすると
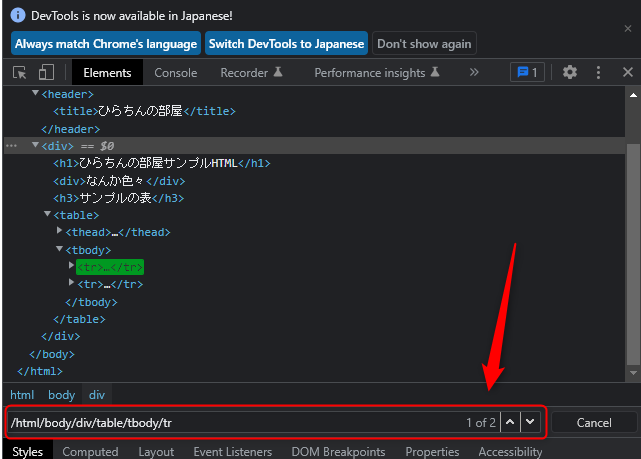
「1 of 2」となり、現在のハイライトは2つのうちの1番目ですよ~ということになります。
Seleniumで表現する場合、
そのまま、2つのtrタグを取得したいときは、
FindElementsByXpath(“/html/body/div/table/tbody/tr”)
と複数を取得するメソッドに変更します。
また、この2つのうちの2番目のtrタグを取得したい場合は、
FindElementsByXpath(“/html/body/div/table/tbody/tr”)
とSelenium側のメソッドで「(2)」を付けて
FindElementsByXpath(“/html/body/div/table/tbody/tr“) (2)
として、2番目を指定するか
そもそもXPathの時点で「[2]」を付けて、
FindElementByXpath(“/html/body/div/table/tbody/tr[2]“)
2番目を指定しておくかで取得出来ます。
ただし、ここで注意して欲しいのは、Selenium側のメソッドで取得する場合は、
複数形で取得して、取り出すときに○番目を取得するので、「FindElementsByXPath」で複数のtrタグを取得していますが、
XPathの時点で2番目を指定してしまう場合は、Selenium側では、最終的に単数の要素での取得になるので「FindElementByXPath」と単数系のメソッドを使用します。
省略して書く
ここまで読ん頂いた人の中には、
「いちいち、HTMLの階層を全部チェックしてたら、めんどくせーじゃん!何が便利なん??」
と思った方も居るはずです。
そう思った方は正しい(^o^)
ここまで、説明したXPathの書き方は、「便利さゼロ」「柔軟性ゼロ」の一番面倒な絶対XPathの書き方です。
基本が大事!ということで書いています。
XPathの便利さが分かるのはここからなので、もう少しお付き合いください。
では、ここまでで説明したXPathの書き方を「短く省略して書く」方法を説明します。
省略するときに使う記号は「//」と「*」の2つです。
2個連続のスラッシュとアスタリスクですね(^o^)
それぞれ分かりやすく表現すると
「 // 」は省略
「 * 」は何でもOK
という意味です。
よく分からないと思うので、実際に見ていきましょう!
改めて、次の図の「div」タグの取得を考えます。
絶対XPathで表現すると
/html/body/div
でしたね。
「//」を使うと要素が省略出来ます。
例えば、「html」タグを省略して書きたい場合は、
//body/div
となります。
つまり、「body」より前の要素は省略します!という意味になります。
実際に、デベロッパーツールに入れてみると
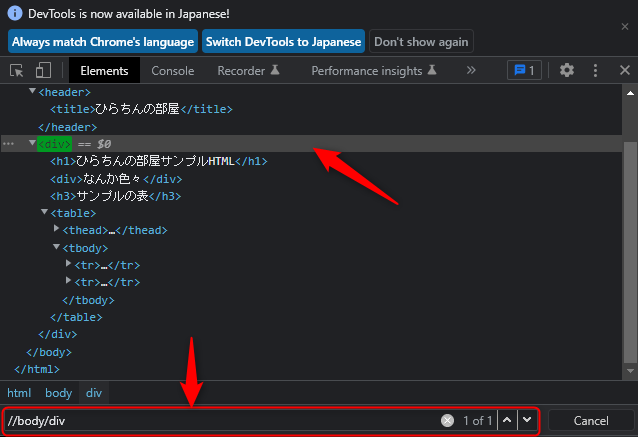
ちゃんとヒットしてますね(^o^)
では、「body」も省略して次のように書いたらどうなるでしょうか。
//div
実際に、デベロッパーツールで確認すると
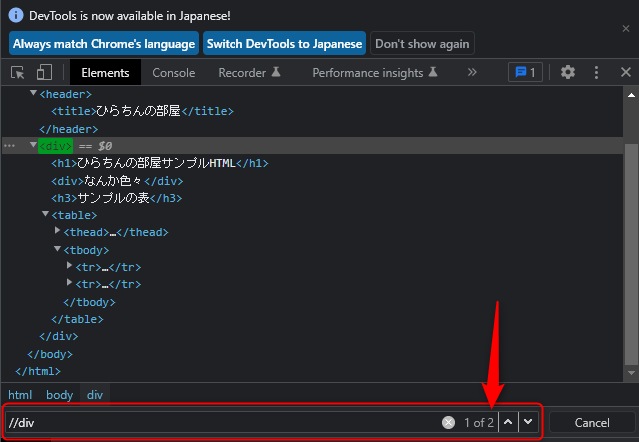
2つの要素がヒットしていることが分かります。
もう一つの要素は

どうやらこいつみたいですね。
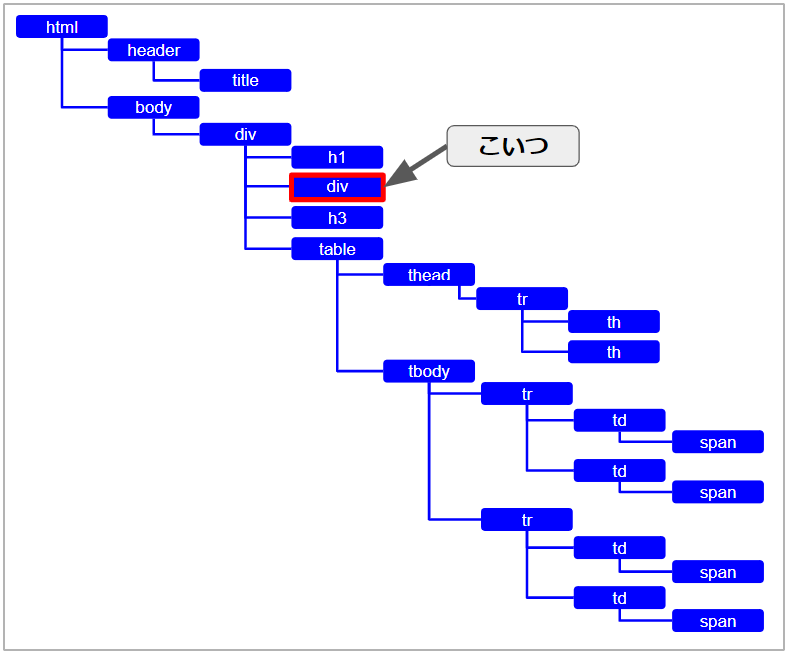
なぜこのようなヒットの仕方になるかというと、「div」タグより前がすべて省略されて記載されているので、「body」の下の「div」タグも、その「div」タグの下の「div」タグも同じ形になってしまうからです。
/html/body/div => //div
/html/body/div/div => //div
逆に言うと、ページ上のすべての「div」タグを取得したい場合は
//div
でOKということになります。
これは、途中で省きたくなっても使えます。
例えば、こんな感じです。
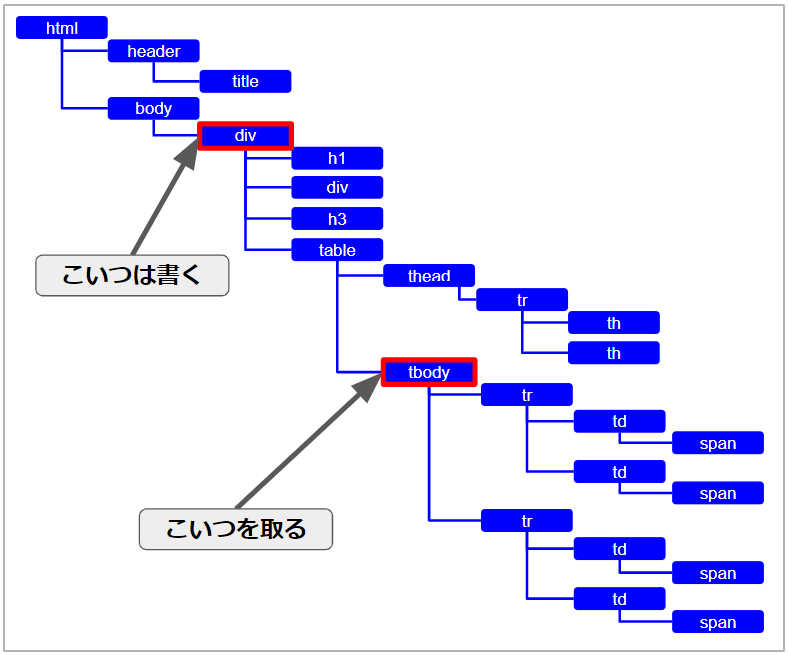
つまり
//div//tbody
こう。
省略 > div > 省略 > tbody
ですね。

しっかり取れてるのが分かります。
次は「*」何でもOKの方です。
例えば、次の図で記した2つの要素を指定したいとします。
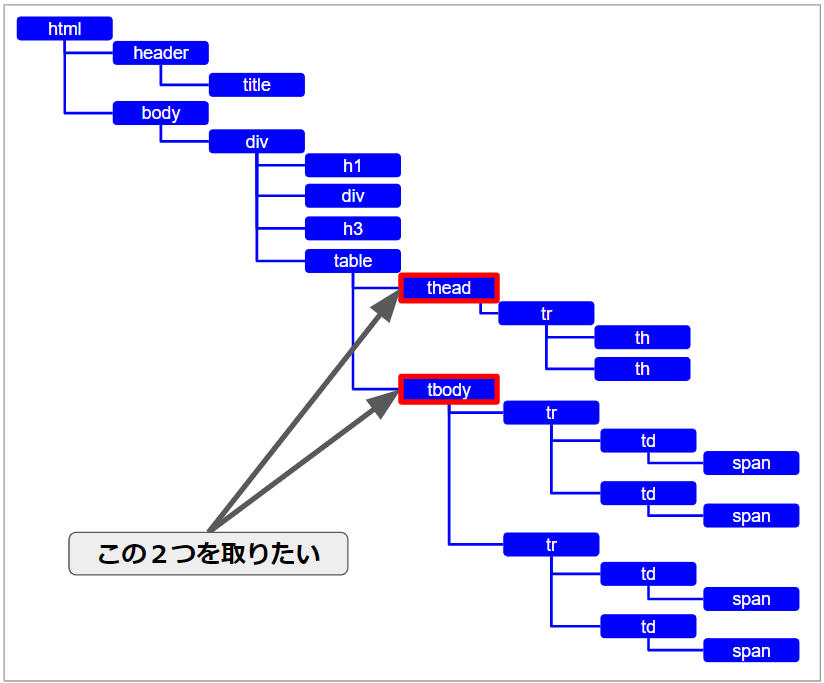
タグ名が違いますよね。
順番にやっていきます。
取りたいタグの1つ上「tableタグ」までは、
//table
で良いですね。
そこから次の階層のタグなので、もう1個「/」を入れて
//table/
です。
これでは、何のタグ取るか分からないのでヒットは0です。
でどのタグ取る?
ここで、「*」何でもOKが登場します。
//table/*
図の中では、tableタグの1つ下の階層には、取りたいタグしか無いので「何でもOK」ですね。
実際に、デベロッパーツールで確認します。
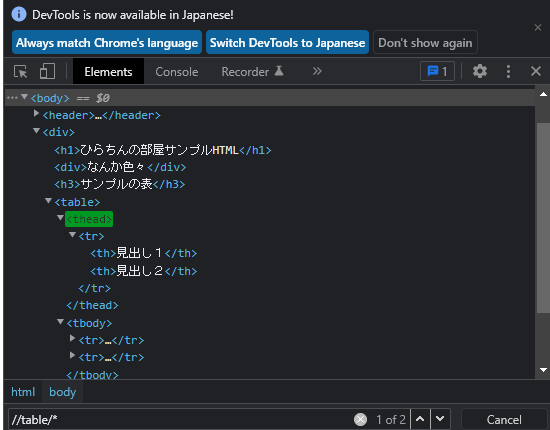
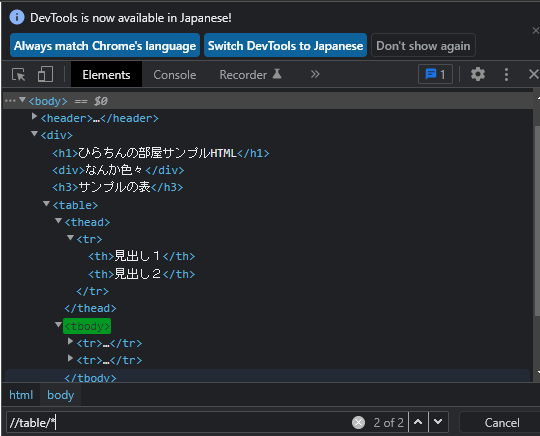
取りたかった、theadタグとtbodyタグが取れていますね(^o^)
テキストで指定する
Xpathでは、ブラウザで表示されているテキストを使って要素を指定することも出来ます(^o^)
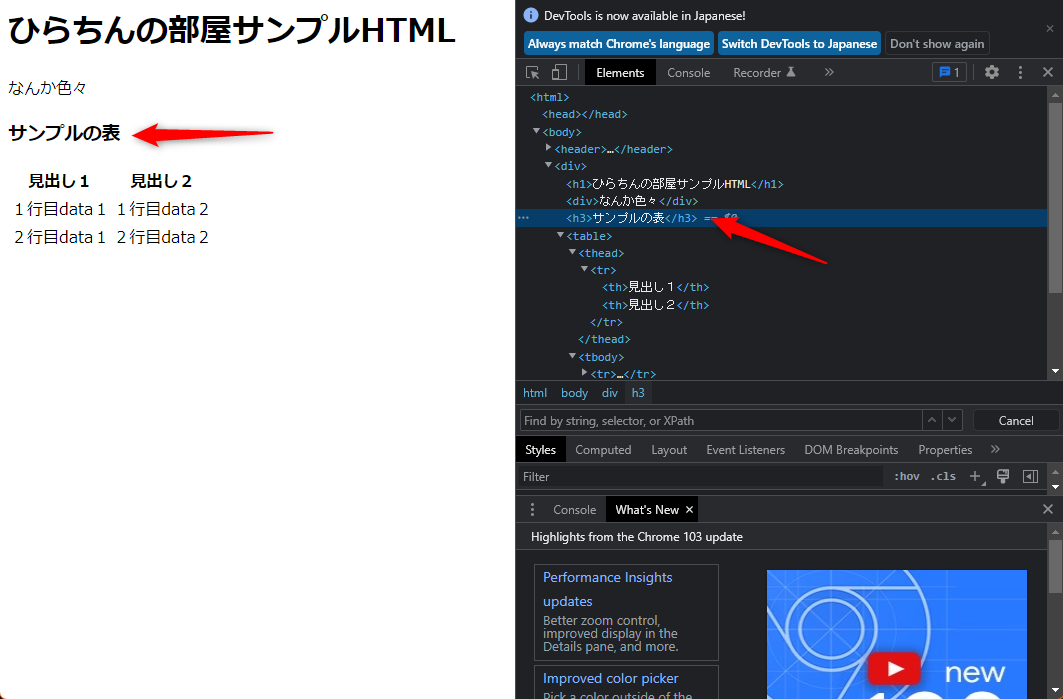
例えば、次の図のように画面上で「サンプルの表」となっている要素です。
デベロッパーツールで確認すると、h3タグですね。
これを、テキストを使って取得してみましょう!
テキストで取得するには、
タグ名[text()=’取得したい要素のテキスト‘]
という形で表記します。
タグ名は探してる要素のタグ名です。
取得したい要素のテキストの部分に、取得したい要素のテキストをいれます。
今回は、「サンプルの表」ですね。
つまり、ここでは次のような形になります。
//h3[text()=’サンプルの表‘]
このタグ名の後ろの [] は、この中に色々な条件を入れるのにこれからもいっぱい使います。
ちなみに、文字列を囲う記号は「” “」ダブルクォーテーションでも「’ ‘」シングルクォーテーションでもどちらでも良いですが、VBAで使うときにXpathでダブルクォーテーションを使うと、VBEに入れたときに「”” “”」と2回続けて書くようにしないといけなくなるので、「’ ‘」シングルクォーテーションで統一することをオススメします。
デベロッパーツールで「’ ‘」シングルクォオーテーションでXpathを確認すれば、VBEにそのままコピペ出来ます(^o^)
実際にデベロッパーツールで確認します。
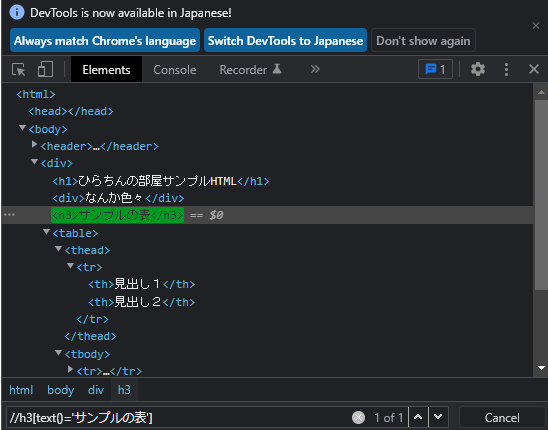
いけてますね(^o^)
サンプルは、h3タグが1個しか無いのでぱっとしないですね。。。
タグ名を「何でもOK」の「*」にしてみましょう!
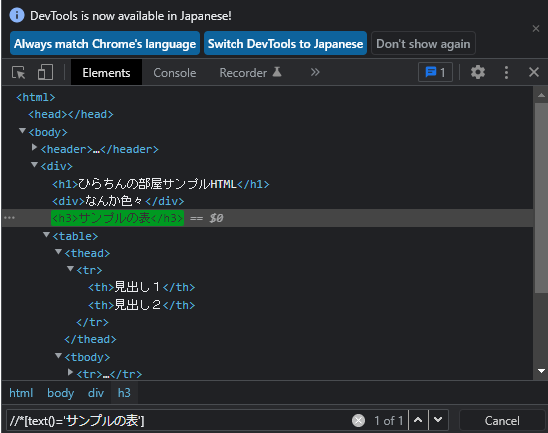
取れました。
こっちの方が、やったった感ありますねw
属性を使って指定する
次に、属性を使った指定の方法です。
「class=なんちゃら」とか、「name=なんちゃら」とか、「id=なんちゃら」とか、「href=なんちゃら」とか、「rel=なんちゃら」とか、タグ名の後ろに色々書いてあるやつです。
最近のHTMLは、属性の種類も多くてアレですが、何でもいけるんで逆に超便利ですよ(^o^)
これまでのサンプルには、属性などは、全く書いてなかったのでちょっと修正します。
たくさん入れると分かりにくいので、classだけ適当に追加。
<header>
<title>ひらちんの部屋</title>
</header>
<body>
<div>
<h1 class="title">ひらちんの部屋サンプルHTML</h1>
<div class="caption">なんか色々</div>
<h3 class="table-title">サンプルの表</h3>
<table class="">
<thead class="header">
<tr class="header-tr">
<th class="header-midashi">見出し1</th>
<th class="header-midashi">見出し2</th>
</tr>
</thead>
<tbody class="body">
<tr>
<td class="body-td1">
<span>1行目data1</span>
</td>
<td class="body-td1">
<span>1行目data2</span>
</td>
</tr>
<tr>
<td class="body-td2">
<span>2行目data1</span>
</td>
<td class="body-td2">
<span>2行目data2</span>
</td>
</tr>
</tbody>
</table>
</div>
</body>
</html>本当に適当に追加していますので、特に意味はありません。
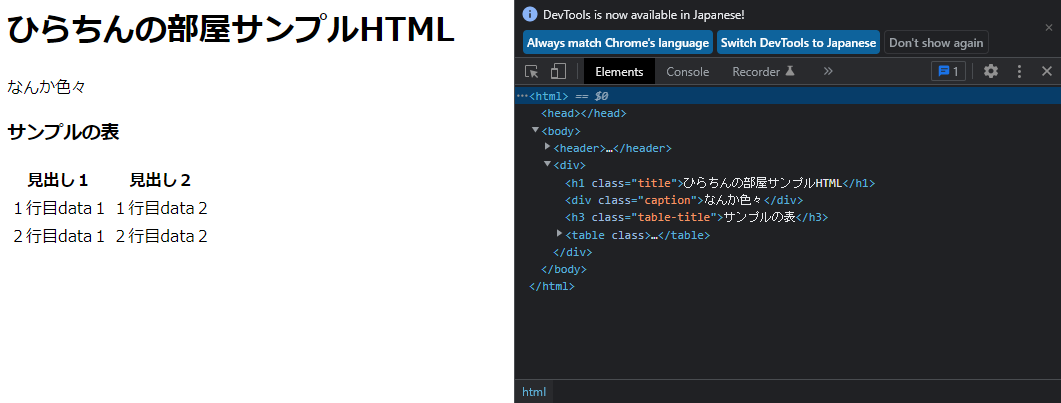
もちろん、ブラウザ上の見た目も変わりません。。。
ぐっと見にくくなりましたね。。。
では早速。
属性を使った指定の方法を紹介していきます。
属性を使った、要素の指定は、次のような形になります。
タグ名[@属性名=’属性の値‘]
テキストで指定したときの、text() が、@属性名 になっただけです。
図の要素を取得することを考えてみましょう。
2つ目のtrタグの下のtdタグですね。
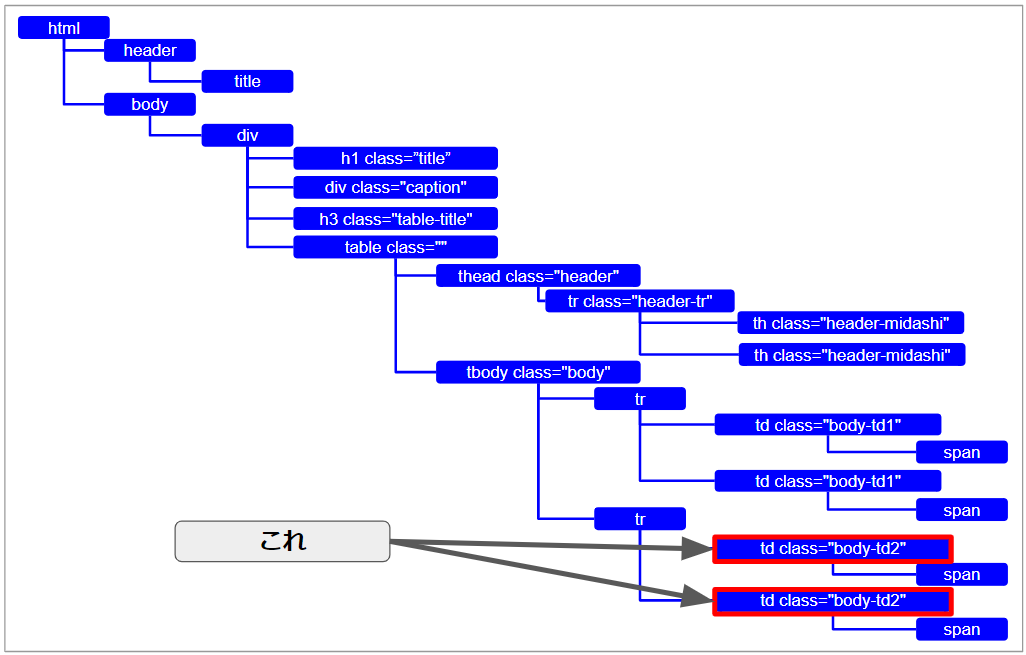
class名は「dody-td2」となっています。
さっきの構文に当てはめてXpathを作ってみます。
//td[@class=’body-td2′]
tdタグの前はすべて省略。
属性名は「class」
属性値は「body-td2」
簡単ですね(^o^)
デベロッパーツールで確認します。

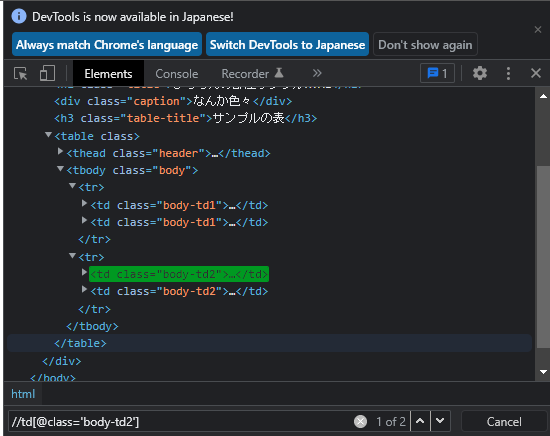
狙っていた2つの要素がヒットしています。
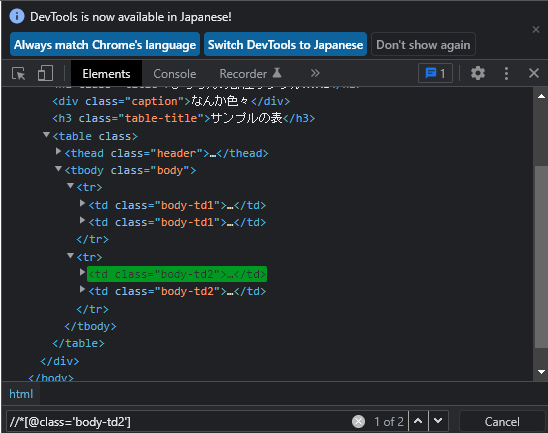
もちろんですが、このサンプルでは、このtdタグ以外に同じclass名を使っている要素はありませんので、タグ名は省略してもOKです。
//*[@class=’body-td2′]
まとめ
Xpathでの要素の指定方法の基本的なことを紹介しました!
次回は、もう少し複雑な条件で要素を指定する方法を紹介したいと思います!
コメント
[…] XPathのわかりやすいサイト […]