Scrapyの使い方
WEBサイトのクローリングやスクレイピングに使える、Scrapeyの使い方です。
環境
- Windows11
- anaconda3
- python3
- VScode
Scrapyのインストール
まずは、コマンドプロンプトから、次のコマンドでScrapyをインストールします。
※VSCodeから実行しています。
conda install -c conda-forge scrapy「Enter」で進めます。
「y(Yes)」で進めます。
入りました。
基本的な流れ
はい、では早速Scrapyを使っていきましょう!
Scrapyの使い方の基本的な流れは下記です。
- プロジェクトの作成
- スパイダーの作成
- itemsを定義する
- 各種設定
- 実行・ファイル出力
プロジェクトの作成
プロジェクトを作るには、次のコマンドを実行します。
scrapy startproject <プロジェクト名>プロジェクト名は「sample」にします。
scrapy startproject sample※ここでは、c:/ひらちんの部屋/scrapy_sampleをカレントディレクトリとして実行します。

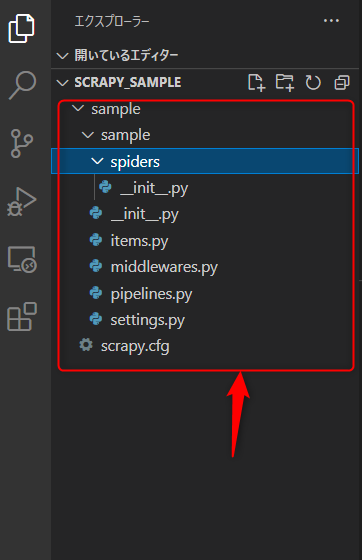
カレントディレクトリに、次のようなプロジェクトが作成されます。
startproject のときに、次のようにすることでプロジェクトを作成するディレクトリを指定することも出来ます。
scrapy startproject <プロジェクト名> [指定のディレクトリ]スパイダーの作成
次にスパイダーを作成します。
スパイダーは、クローリングやスクレイピングの流れを書いていくためのファイルです。
次のコマンドで実行します。
scrapy genspider [-t テンプレート] <スパイダー名> <ドメイン>スパイダー名に、sample_spider
ドメインには、アルバイト情報サイトのバイトルさん(baitoru.com)を指定します。
[-t テンプレート]は、作成されるファイルのテンプレートの指定ですが、ここでは省略します。
※省略するとbasicのテンプレートになります。
以下のコマンドを実行します。
scrapy genspider sample_spider baitoru.comこのコマンドは、プロジェクトディレクトリで実行する必要があるので、先程作ったsampleディレクトリに移動しておきましょう。



実行すると、スパイダー名で指定した「sample_spider.py」ファイルが作成されます。
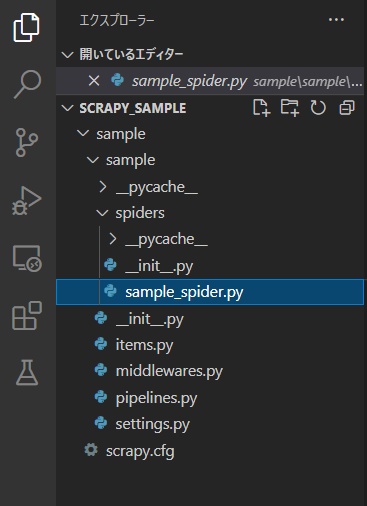
中身は次のようになっています。
import scrapy
class SampleSpiderSpider(scrapy.Spider):
name = 'sample_spider'
allowed_domains = ['baitoru.com']
start_urls = ['http://baitoru.com/']
def parse(self, response):
pass
「start_urls」に指定されている、URLは”http”で設定されるので、”https”の場合は修正する必要があります。
後ほど、このファイルを修正して、クローリングやスクレイピングの処理を記述していきます。
itemsを定義する
既に出来上がっている「items.py」ファイルにサイトから取得したい項目を追記します。
こいつを使って後で取得したデータを整理します。
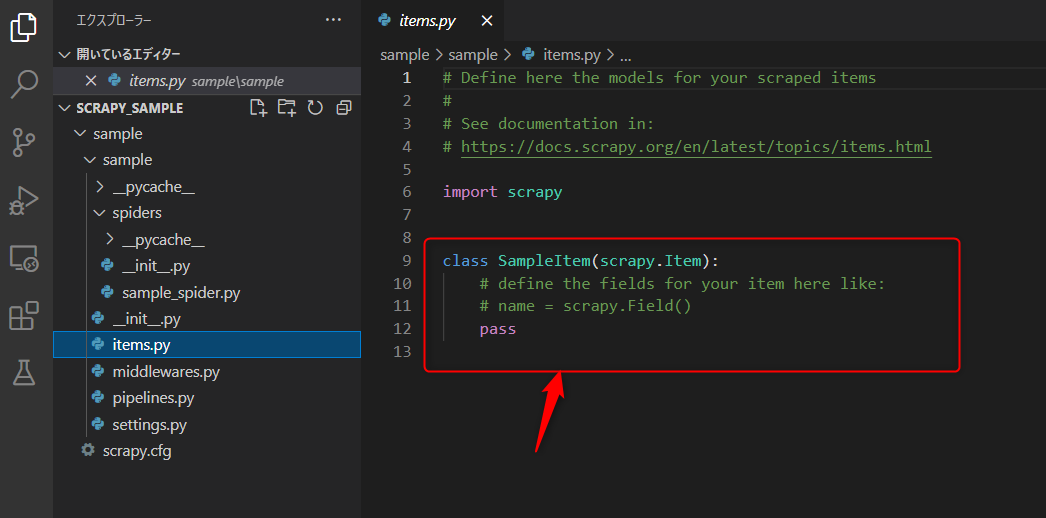
変数名=scrapy.Field() の形で記述します。
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class SampleItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
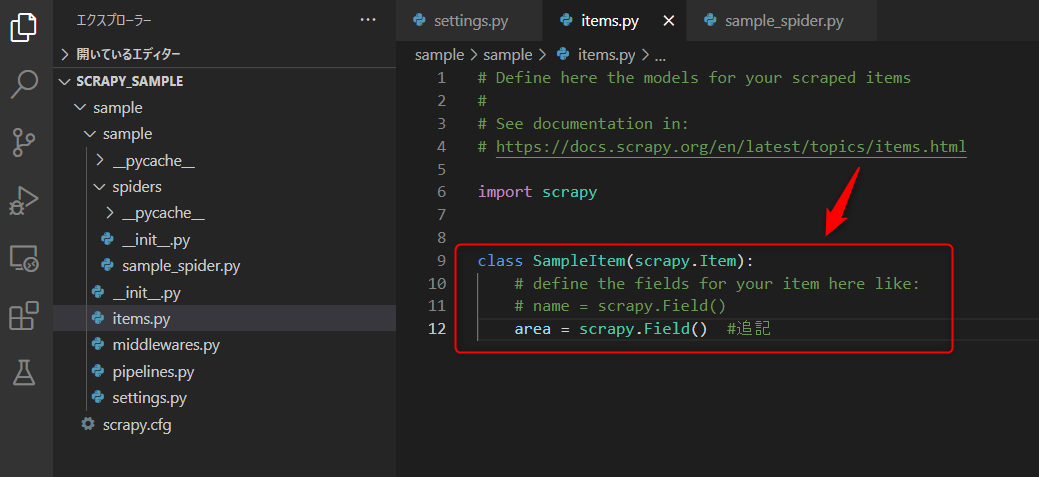
area = scrapy.Field() #追記「area」を追加しました。
合わせて、スパイダー(sample_spider.py)の方も修正します。
サイトからなんのデータを取得して、どの項目に入れるかって感じですね。
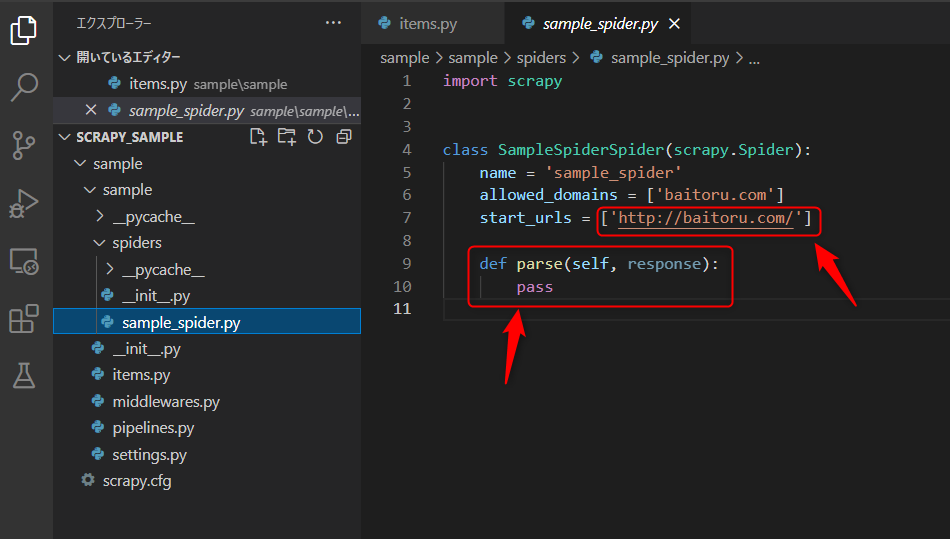
次のように修正します。
import scrapy
from sample.items import SampleItem
class SampleSpiderSpider(scrapy.Spider):
name = 'sample_spider'
allowed_domains = ['baitoru.com']
start_urls = ['https://baitoru.com/']
def parse(self, response):
for res in response.xpath('//*[@id="link_job_list_pc_all_all_maps"]//li/a'):
item = SampleItem()
item['area'] = res.xpath('.//text()').get()
yield item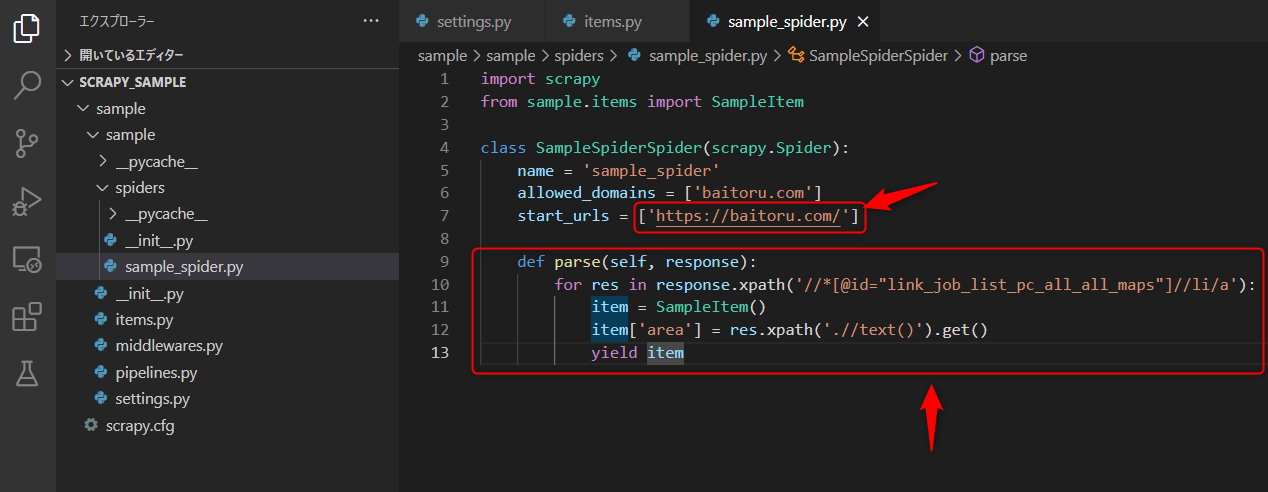
start_urls は”http”を”https”に変更しているだけです。
parseメソッドの方についてですが、スパイダーはまず start_urls で指定されたURLにリクエストします。
そして、返って来るレスポンスを、parseメソッドのところにある引数の”response“で受け取るという流れです。
response.xpath('//*[@id="link_job_list_pc_all_all_maps"]//li/a')
この部分で、レスポンスの中からxpathで指定した要素をセレクターオブジェクトとして取り出しています。
※ここでは、要素の取り出し部分は詳しくやりません。。。悪しからず
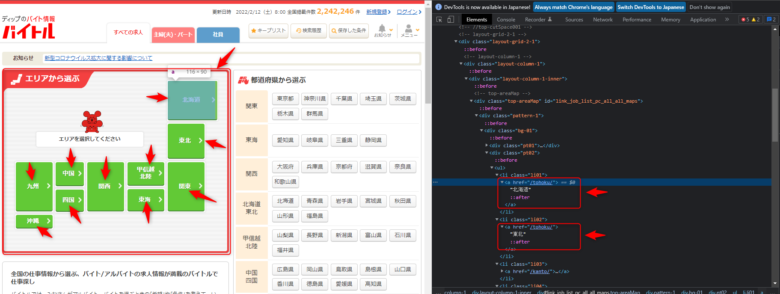
printで吐き出すとこんな感じです。

複数のセレクターオブジェクトがリスト形式で取得出来るため、for で回します。
回した後は、先程「items.py」で作った、雛形に入れる感じです。
item = SampleItem() でSampleItemを使えるようにして
item['area'] = res.xpath('.//text()').get() で値をぶち込みます。
今回、雛形には「area」しか作ってないので1つだけですが、複数作ってそれぞれぶち込んでください。
※セレクターオブジェクトに対してXpathを使う場合は、初めに「.」がいるのでご注意を。
各種設定
Scrapyの様々なオプションの設定をします。
「settings.py」ファイルを編集します。
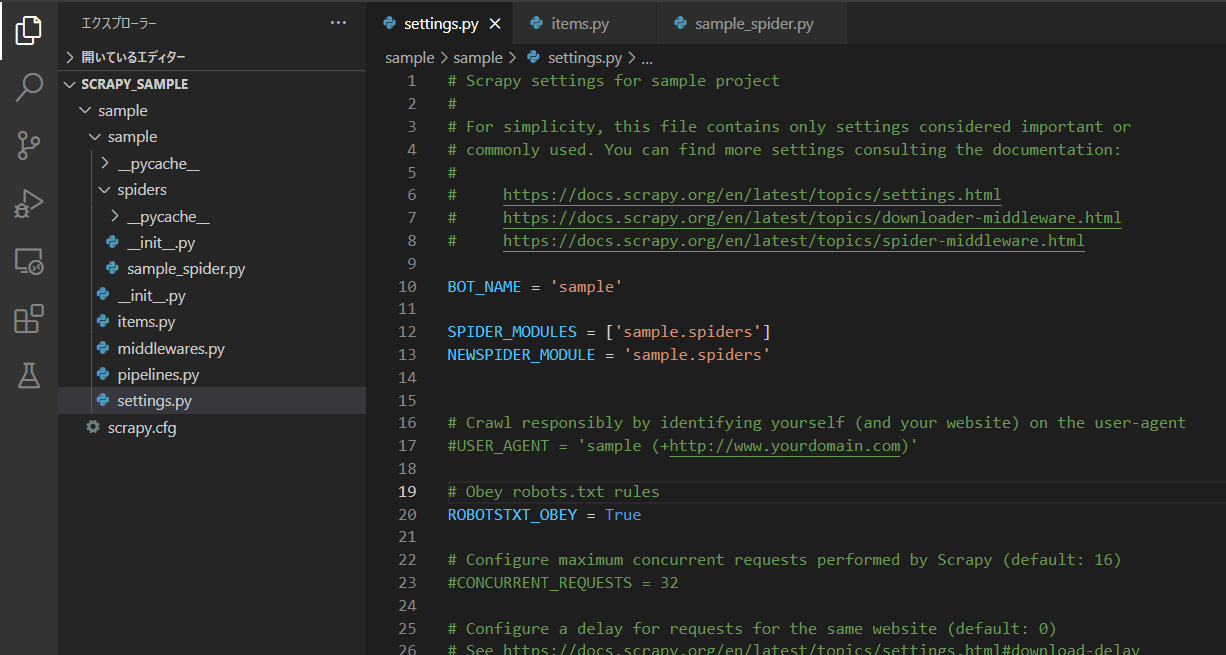
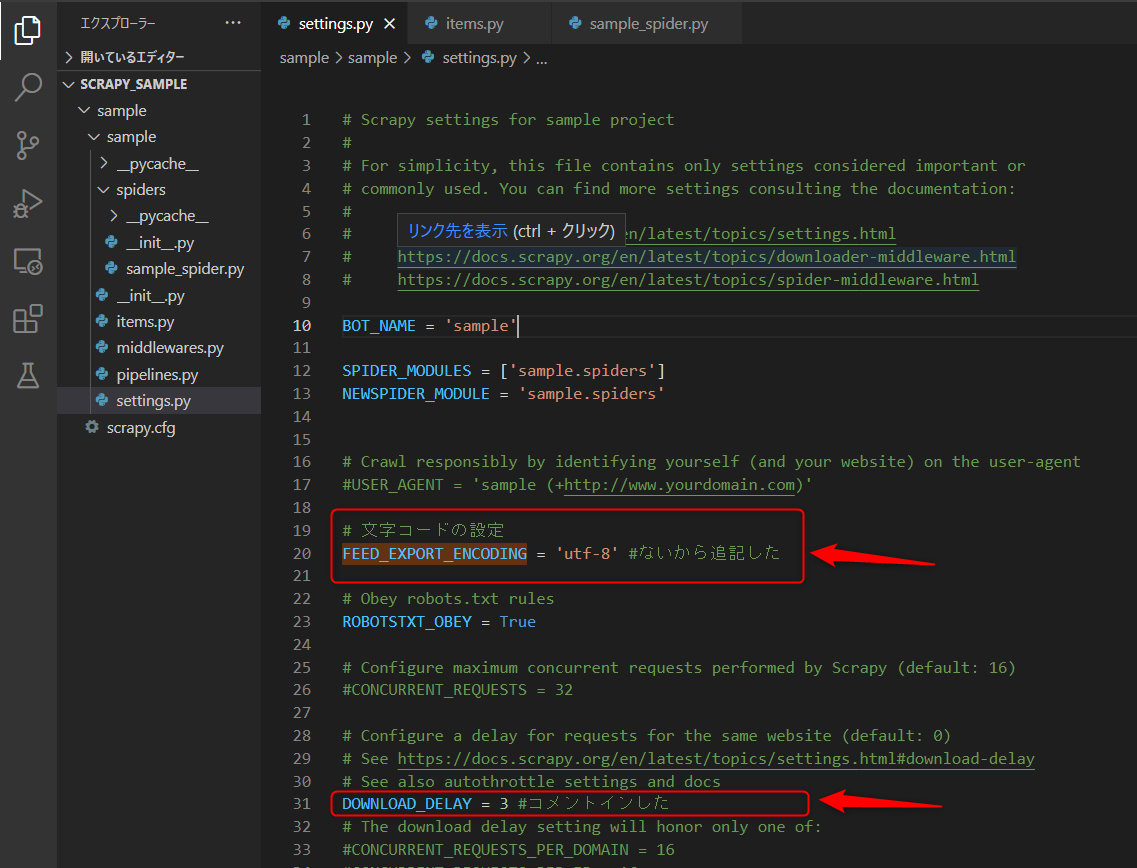
文字コードの設定
文字化けしないようにFEED_EXPORT_ENCODING = 'utf-8'を設定して、文字コードを標準的な”utf-8″に設定します。
ダウンロード間隔の設定
サーバーに対して負荷をかけすぎないように、DOWNLOAD_DELAY = 3
実行・ファイル出力
それでは実行しましょう!
実行するには次のコマンドを実行します。
scrapy crawl <スパイダー名><スパイダー名>は「sample_spider」なので次のようにします。
scrapy crawl sample_spider
実行すると
ターミナル上で色々出てきますが、次の部分をご覧下さい。
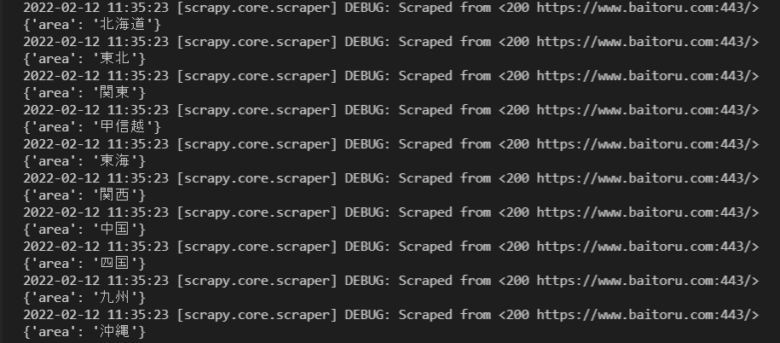
取得したaタグのテキストが取得出来ています。
簡単ですね(^o^)
また、Scrapyでは、これをファイルとして出力するのも簡単です。
先程の実行コマンドに次のように-oオプションを指定することで、ファイル名に指定した拡張子の形式でファイル出力が行われます。
scrapy crawl <スパイダー名> -o <ファイル名.拡張子>.json.xml.csv.jlまたは.jsonl⇒ JSON Lines.pickle
このへんがいけます。
みんな大好きJSONでやってみましょう!
scrapy crawl sample_spider -o test.json
実行すると、
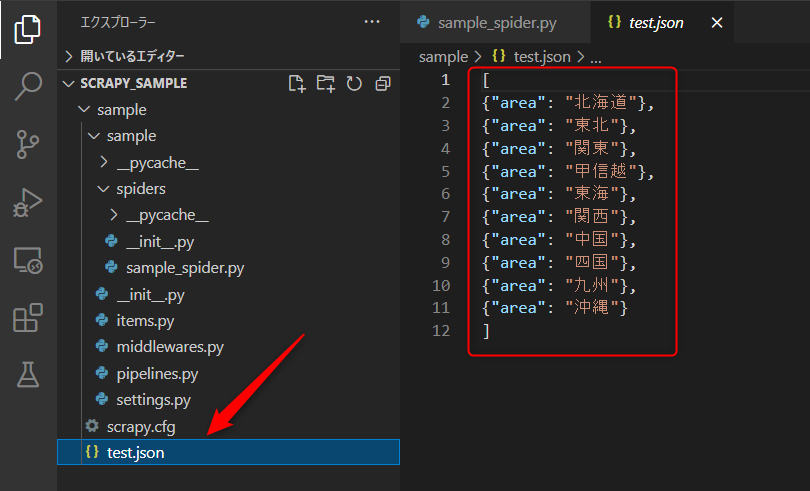
JSONファイルが作成されて、データが保存されます。
CSVではどうでしょうか。
scrapy crawl sample_spider -o test.csv
実行すると
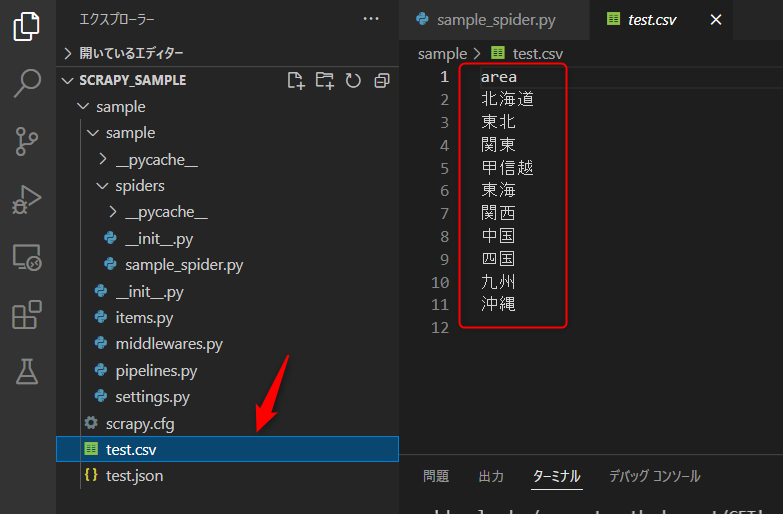
項目1つなんでコンマがなくて分かりにくいですが、、、
csvファイルが生まれて保存されます。
まとめ
Scrapyを使って、クローリング・スクレイピングをする方法について紹介しました!
ここからスパイダーに処理の流れを書くことで、色々なデータを取得することが可能です!
要素の取得方法などは、別記事で追々やりたいと思います。。。
コメント
初めまして、giyaoといいます。Scrapyを習得したいと思い、こちらで学ばせていただきました。
とても理解しやすかったのですが、以下の部分を、どうしたらよいのか分からないので、ご教授ください
今回、雛形には「area」しか作ってないので1つだけですが、複数作ってそれぞれぶち込んでください。
宜しくお願い致します。
コメントありがとうございます!
お返事遅くなりましてすみません!!
ご質問の件ですが、以下のようになります
雛形 => class SampleItemの中です。
今
「area = scrapy.Field()」
となっている次の行に
例えば
「hoge = scrapy.Field()」
みたいに追加します。
それから、今度は
class SampleSpiderSpider
の中の
def parseにある
item[‘area’] = res.xpath(‘.//text()’).get()
のように
item[‘hoge’] = res.xpath(‘取得したいXpathを指定’).get()
みたいにすれば行けると思います!!