WEBページのデータを抜き出す
今回は、WEBページからスプレッドシートにデータを抜き出す関数である、IMPORTHTMLHTML関数を紹介します。
クローラー作るほどでもないな~とか、そういうんは分からないけど、特定ページのデータを一気にスプレッドシートに書き出したいな~とかいう場合に便利に使える関数です(^o^)
IMPORTHTML関数
IMPORTHTML(URL, クエリ, 指数)
URL: 取得したいページのURLを指定します。「”」ダブルクォーテーションで囲います。”http://……”などからちゃんと入れて下さい。(セルへの参照でもOKです!)
クエリ:目的のデータを含むアイテムの種類を “list”(リスト)か “table”(表)で指定します。IMPORTHTMLでは、ページ上のリストタグ(<ol>タグ・<ul>)かテーブルタグ(<table>)のデータを取得します。
指数:対象の表またはリストについて、HTML ソース内で定義されている番号で 1 から順に指定します。ページ内の1つ目のtableタグであれば「1」2つ目なら「2」みたいな感じです。
tableデータ取得サンプル
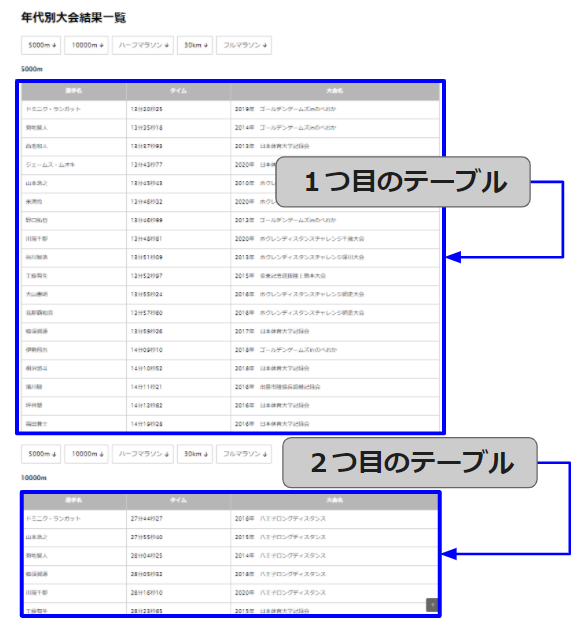
特に意味はないのですが、テーブルがいっぱいあるページがあったので次のページからテーブルデータを抜き取ってみます。
HTMLが分かるひとは簡単ですが、<table>…</table>で囲まれたところです。
【サンプルページ】

※コニカミノルタさんの陸上部の記録がいっぱいあるページです。
数式
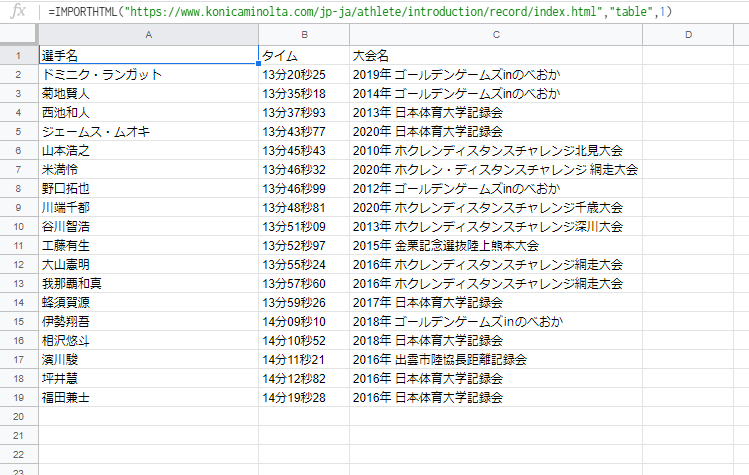
=IMPORTHTML( “https://www.konicaminolta.com/jp-ja/athlete/introduction/record/index.html”, “table”, 1 )
URLは、先程のコニカミノルタさんのページのURLです。「”」ダブルクォーテーションで囲ってくださいね(^o^)
クエリは、テーブルデータを抜き出したいので、「”table”」で指定しています。これも、「”」ダブルクォーテーションで囲います。
指数は、「1」にしていますが、これはテーブルの1つ目を取得するということです。2つ目を取得したかったら「2」にします。(ページ見ていただくと、テーブルデータが何個かあるのが分かると思います。)
https://www.konicaminolta.com/jp-ja/athlete/introduction/record/index.html
先程の数式を、スプレッドシートのA1セルに入力します。
こんな感じで、1つ目のテーブルのデータが表示されます(^o^)
簡単ですね!
listデータ取得サンプル
次に、WEBページ内のリストのデータを取得します。
HTMLのタグで言うところの、<ol>…</ol>や<ul>…</ul>のところです。
次のWEBページから抜き取ってみます。
【サンプルページ】
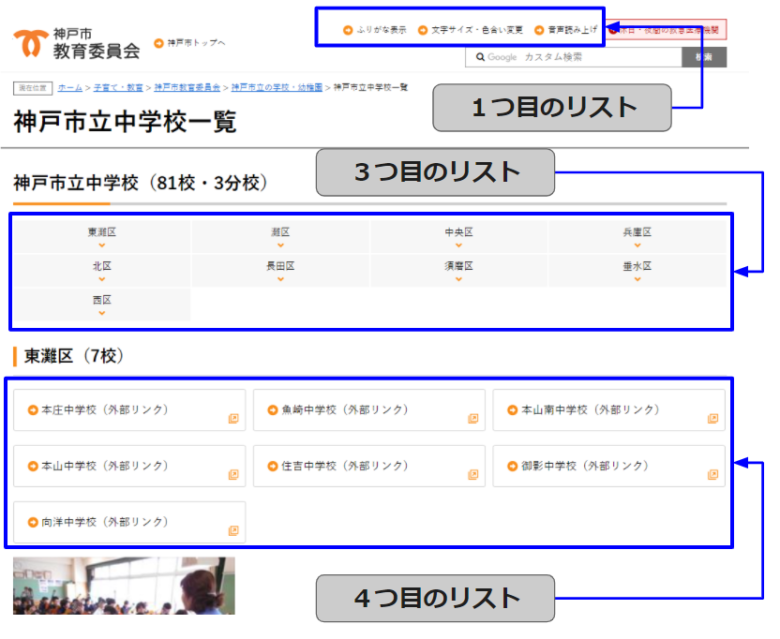
※神戸市教育委員会の神戸市立中学校の一覧のページです。
数式
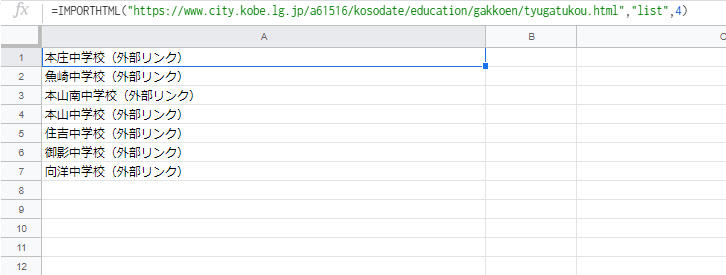
=IMPORTHTML(“https://www.city.kobe.lg.jp/a61516/kosodate/education/gakkoen/tyugatukou.html”,”list”,4)
URLは、先程の神戸市教育委員会のページのURLです。「”」ダブルクォーテーションで囲ってくださいね(^o^)
クエリは、リストデータを抜き出したいので、「”list”」で指定しています。これも、「”」ダブルクォーテーションで囲います。
指数は、「4」にしています。ここでは、4つ目のリストである「東灘区(7校)」のリストを抽出します。
※2つ目のリストが見えませんが、実はスマホ用にメニューのリストがHTMLに隠れています。
数式をスプレッドシートのA1セルに入力します。
次のように、4つ目の「東灘区(7校)」のリストの内容が抽出出来ます。
引数の”URL”、”クエリ”,”指数”をセル参照で取得する
数式をいちいち入れ直したりするのは面倒だな~という方には、引数の情報をセルの参照で行うことも出来ます。
次の図をご覧下さい。
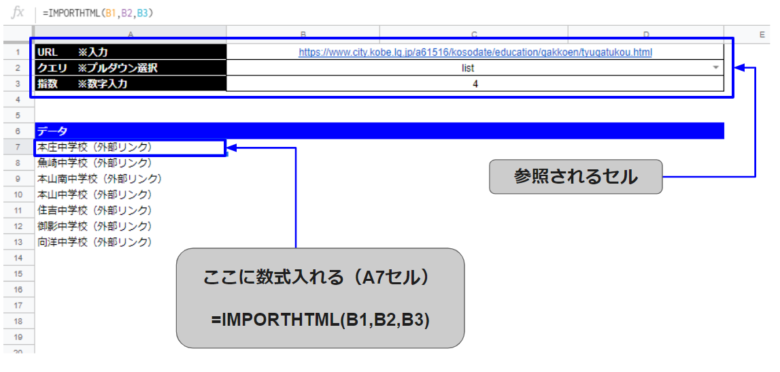
B2セルにURL、B2セルにクエリ、B3セルに指数を指定し、セル上で入力や選択を出来るようにしています。
こうすることで、セルの情報を変えるだけで、結果を色々変更することが出来るようになります。
テーブルやリストが何番目なのか良くわからないときに、色々入れてみて試すのにも便利ですね。
実行動画もご覧下さい。
予め取得したいURLのリストを別のシートかなんかに用意しておいて、切り替えて使ったとかもできそうですね(^o^)
まとめ
IMPORTHTML関数を説明しました。WEBページのリストやテーブルからデータをコピペしてたような方!ぜひ使って下さい(^o^)
コメント