WEBサイトの情報をGASで取得する1
今回は、GASを使ったクローリング・スクレイピングのやり方の紹介です!
WEBサイトをプログラムでデータ収集出来たらな~。でも難しそう。。。。(;_;)
そんな風に思う方もたくさんいるかと思いますので、初心者の方でも出来るようになることを目指して書いていこうと思います!
クローリング・スクレイピングとは
まずはクローリングとスクレイピングの違いについて説明しておきます。
クローリング
クローリングとはWEBサイトを巡回することそのもののことを言います。水泳でもクロールというように、腹ばっていくとか、徐々に進むみたいな意味から来ています。
プログラムがWEBサイトを自動的に巡回して、情報を収集することに使われています。
この、クローリングするためのプログラムのことを「クローラー」とか「スパーダー」とか呼ばれています。
スクレイピング
また、スクレイピングは重要な情報を取得することで、スクレイプとは擦り落とすとか削り落とすみたいな意味があります。
クローラーで巡回して取得してきたHTMLの情報を、必要なタグの値だけ書き出したり、整えて取得したりすることです。
つまり、WEBサイトの情報をクローリングしてスクレイピングするってことですね(^o^)
クローリング・スクレイピングの方法
それでは早速、GASでWEBサイトの情報を取得していきましょう!
プログラムの流れ
大まかなプログラムの流れは次のようになります。
- 情報を取得したいWEBサイトのURLを確認する
- UrlFetchAppクラスを使って、GASからWEBサイトの情報にアクセスする
- 返ってきた情報から必要な情報を抜き出す
- スプレッドシートに書き出す
こんな感じです。
一つずつ行きましょう!
情報を取得したいWEBサイトのURLを確認する
まずは、情報取得したいURLを調べます。これは普通にブラウザでWEBサイトを表示させて、アドレスバーにあるURLを確認します。
「engage」というサイトでやってみましょう。
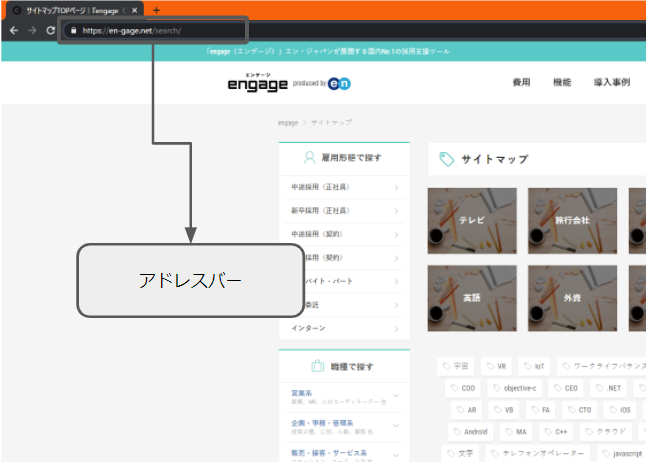
アドレスバーにあるURLはこちらです。

こいつをメモっときましょう。
UrlFetchAppクラスを使って、GASからWEBサイトの情報にアクセスする
次に、プログラムからWEBサイトにアクセスさせる方法です。
GASプログラムでWEBサイトにアクセスするには、UrlFetchAppクラスを利用します。
UrlFetcAppクラスのメソッドは以下です。
| メソッド | 戻り値の型 | 説明 |
|---|---|---|
| fetch(url) | HTTPResponse | urlにアクセスする |
| fetch(url, params) | HTTPResponse | params(オプション)を指定して、urlにアクセスする |
| fetchAll(requests) | HTTPResponse[] | params(オプション)を指定して、複数のurlに複数のリクエストを行います。 |
| getRequest(url) | Object | 操作が呼び出された場合に行われた要求を返します。 |
| getRequest(url, params) | Object | 操作が呼び出された場合に行われた要求を返します。 |
今回は、一番上のfetchメソッドを利用します。
UrlFetchApp.fetch(url)
引数のulrに、確認した「https://en-gage.net/search/」を指定します。
function test(){
// WEBサイトのURLを指定
var url = "https://en-gage.net/search/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセス
var res = UrlFetchApp.fetch(url)
// 返り値resをログに表示
Logger.log(res)
}表示されたログを確認すると、次の図のようにWEBページのHTMLの情報が取れていることが分かります。
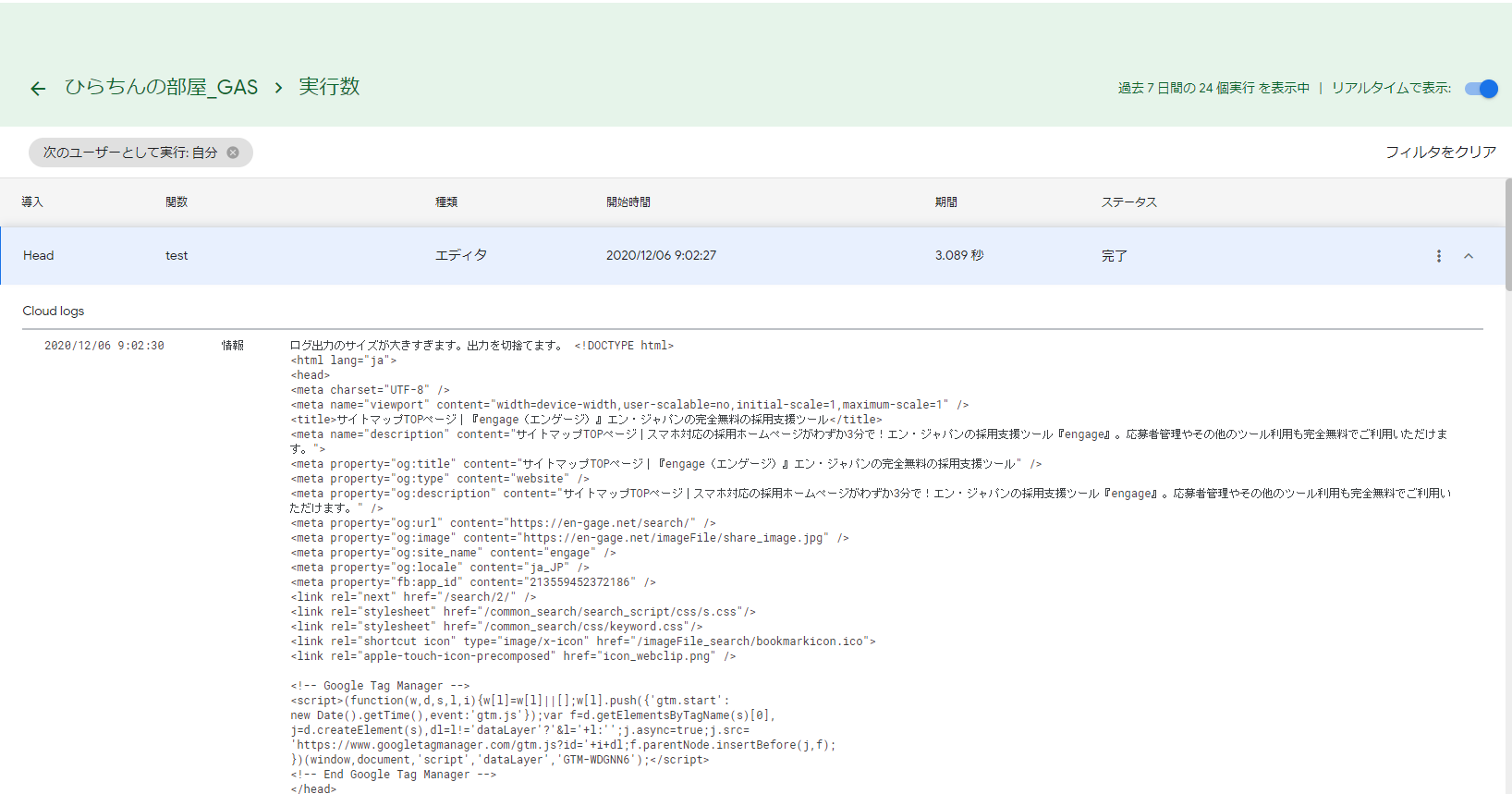
ただし、これはHTTPResponseオブジェクトというオブジェクトです。
スクレイピングするには、文字列情報だけで良いので、次のHTTPResponseクラスのgetContentTextメソッドを使って、文字列の情報だけ取得するのが良いでしょう。
function test(){
// WEBサイトのURLを指定
var url = "https://en-gage.net/search/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセスして、文字列情報として取得する
var res = UrlFetchApp.fetch(url).getContentText()
// 返り値resをログに表示
Logger.log(res)
}返ってきた情報から必要な情報を抜き出す
2.で返ってきたHTMLの情報から、必要な部分を抜き出します。
抜き出す方法は、正規表現を使ってゴリゴリと書くか、ライブラリを使って行うのが主流かと思います。
ここでは、よく紹介されている「Parserライブラリ」を使っていきましょう!
ライブラリとは
先にライブラリって何?って方のために簡単に説明しておきます。
ライブラリとは、プログラムを作る時に全ての機能(関数)を一から自作で作るのは大変なので、よく使われる機能(関数)を汎用的にまとめて、みんなが使えるような状態にしているものです。
このように、先人たちが頑張って作った機能を使うことによって、同じことを後の人がやらなくてよくなるので、開発のスピードがグングン上がっていくんですね!
ということです。
GASでライブラリを使う方法
GASでライブラリを使うためには、スクリプトエディタの「リソース」タブのメニューにある「ライブラリ」で設定する必要があります。
他の言語の開発環境では、プログラム内でimportとかで読み込むんで、ちょっと特殊ですね。
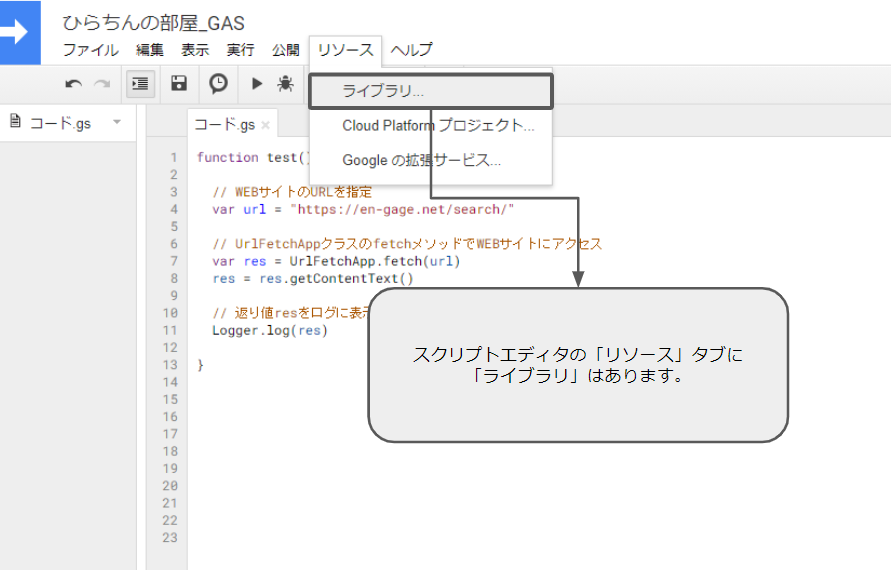
ライブラリに進むと、次のような画面が表示されます。
下の「Add a library」のボックスに、利用したいライブラリのID(プロジェクトキー)を入力して追加ボタンを押します。
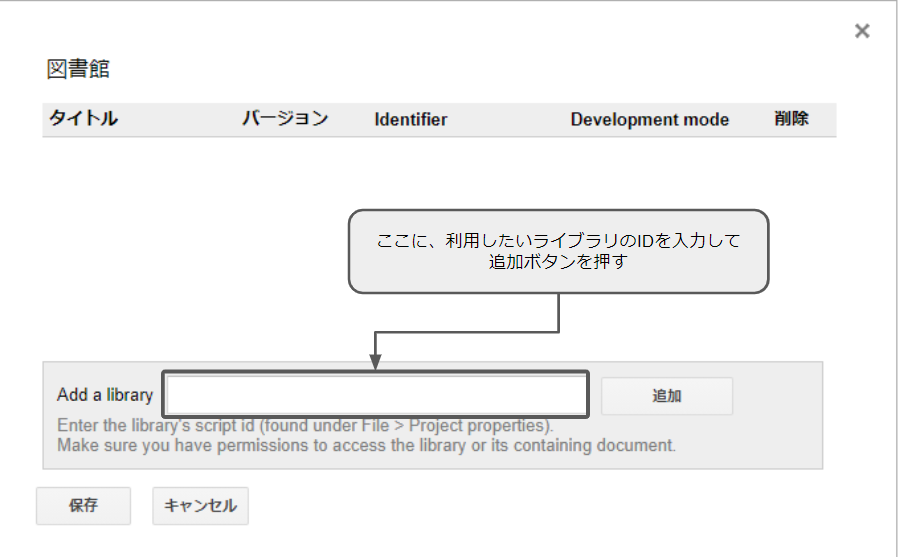
ライブラリのID(プロジェクトキー)は、WEBサイトなどで検索すると色んな方が紹介してくれてますので「GAS ライブラリ *やりたいこと*」みたいな感じで探すと分かります。
探したところ、ParserライブラリのID(プロジェクトキー)は次です。
M1lugvAXKKtUxn_vdAG9JZleS6DrsjUUV
こいつを、先程のボックスに入れて、追加ボタンを押します。
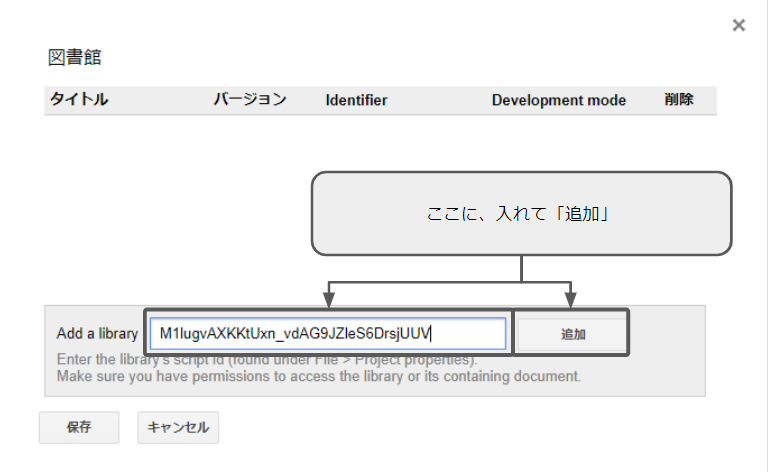
次のような画面になりますので、ライブラリの名前がちゃんと合ってるか確認して、バージョンを選択して、有効化します。
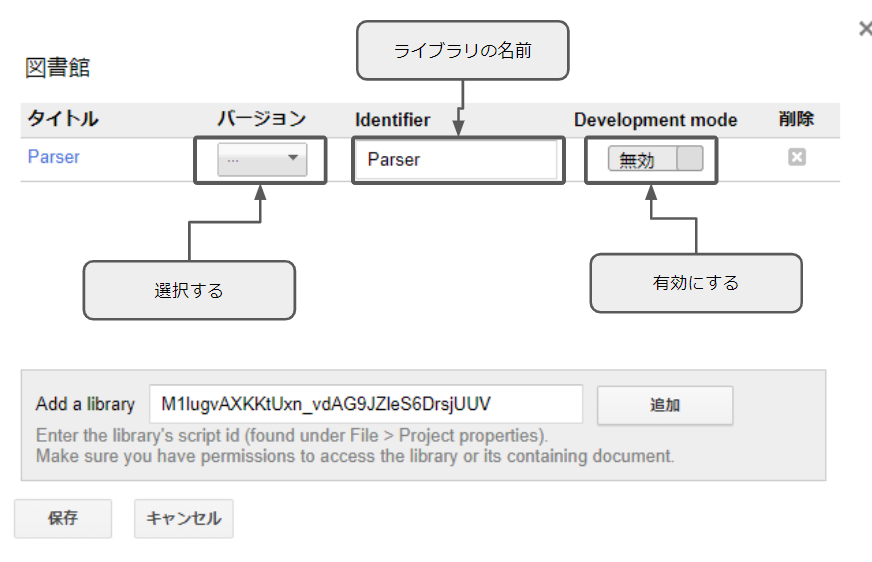
バージョンを押すと、ここでは7と8が出てきました。

特にこだわりがなければ、数字の大きいほうが新しいバージョンなので、大きい方を選んどきましょう。ここでは「8」を選びます。
次の、Development modeを有効にします。
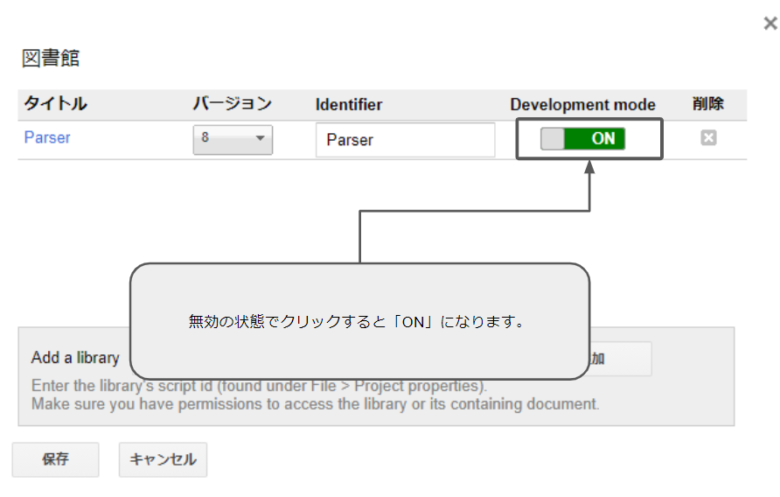
「無効」の状態でクリックすると「ON」になります。
最後に、左下にある「保存」ボタンを押してOKです。
これで、Parserライブラリが使えるようになりました。
Parserライブラリの使い方
Parserライブラリの使い方は次のようになっています。
インスタンスの生成の方法
Parser.data(content)
引数のcontentは文字列型で指定する。.getContentText()で文字列型で取得出来ましたね。
var html = UrlFetchApp.fetch('https://hogehoge/').getContentText();
var parser = Parser.data(html);ここで格納したdata(変数で言うところのperser)がパースの対象になっていきます。
サンプルのコードは次のようになります。
function test(){
// WEBサイトのURLを指定
var url = "https://en-gage.net/search/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセスして、文字列情報として取得する
// resはHTMLの情報
var res = UrlFetchApp.fetch(url).getContentText()
// Parserオブジェクトの生成
var parser = Parser.data(res)
}パターンでの文字列抜き出し
文字列を抜き出すには、次のようなメソッドを組み合わせます。
抜き出し開始の文字列パターンを指定する
.from(pattern, [offset])
引数patternに抜き出しを開始したい文字列のパターンを指定します。オプションのoffsetは数字(デフォルトでは0)で指定します。指定すると、抜き出す文字列を指定文字数分ずらすことが出来ます。
抜き出しの最後の文字列パターンを指定する
.to(pattern, [offset])
引数patternに抜き出しを終えたい文字列のパターンを指定します。オプションのoffsetは数字(デフォルトでは0)で指定します。指定すると、抜き出す文字列を指定文字数分ずらすことが出来ます。
抽出の実行(最初に見つかったもの)
.build()
fromやtoのメソッドの最後に書いて抽出を実行します。この場合最初に見つかったものが返されます。
抽出の実行(リスト/ヒットするもの全て)
.iterate()
これもfromやtoのメソッドの最後に書いて抽出を実行します。この場合はヒットするものが全てリスト(配列)で返されます。
簡単な例
例えばこんなHTMLがあったとします。
<ul>
<li>カレー1</li>
<li>ハンバーグ1</li>
<li>オムライス1</li>
</ul>
<ul>
<li>カレー2</li>
<li>ハンバーグ2</li>
<li>オムライス2</li>
</ul>次のコードで抽出を実行してみます。
HTMLはテストなので、ベタ打ちで変数htmlに入れています。通常は、ここをUrlFetchApp.fetch(url).getContentText()で取得します。
function test(){
// HTMLの情報
var html = "<ul>" +
"<li>カレー1</li>" +
"<li>ハンバーグ1</li>" +
"<li>オムライス1</li>" +
"</ul>" +
"<ul>" +
"<li>カレー2</li>" +
"<li>ハンバーグ2</li>" +
"<li>オムライス2</li>" +
"</ul>"
// Parserオブジェクトの生成
var parser = Parser.data(html)
// 抜き出し
var res = parser.from("<li>").to("</li>").build()
// ログに出力
Logger.log(res)
}「// 抜き出し」の部分のコード
var res = parser.from(“<li>”).to(“</li>”).build()
ここを見てください。
という意味になります。
ログを確認すると、最初に<li><li/>で挟まれている「カレー1」が出力されていることが分かると思います。
.build()を.iterate()に変えるとどうなるか確認します。
var res = parser.from(“<li>”).to(“</li>”).iterate()
function test(){
// HTMLの情報
var html = "<ul>" +
"<li>カレー1</li>" +
"<li>ハンバーグ1</li>" +
"<li>オムライス1</li>" +
"</ul>" +
"<ul>" +
"<li>カレー2</li>" +
"<li>ハンバーグ2</li>" +
"<li>オムライス2</li>" +
"</ul>"
// Parserオブジェクトの生成
var parser = Parser.data(html)
// 抜き出し
var res = parser.from("<li>").to("</li>").iterate()
// ログに出力
Logger.log(res)
}実行すると、ログにリスト(配列)で次のように出力されます。
[カレー1, ハンバーグ1, オムライス1, カレー2, ハンバーグ2, オムライス2]
<li>と</li>で挟まれている部分が全て抽出されていますね。
基本的には、ここまで紹介してきたメソッドで、HTMLの構造とにらめっこしながら組み合わせて、自分の欲しい情報を抽出出来るロジックを組み立てていくといった感じですが、他にも便利なメソッドがあるので、おまけで紹介しておきます。
.offset(index)
.detaで格納している文字列にオフセットを指定する。
function test(){
// HTMLの情報
var html = "<ul>" +
"<li>カレー1</li>" +
"<li>ハンバーグ1</li>" +
"<li>オムライス1</li>" +
"</ul>" +
"<ul>" +
"<li>カレー2</li>" +
"<li>ハンバーグ2</li>" +
"<li>オムライス2</li>" +
"</ul>"
// Parserオブジェクトの生成
var parser = Parser.data(html)
// 抜き出し
var res = parser.offset(8).from("<li>").to("</li>").iterate()
// ログに出力
Logger.log(res)
}.offset(8)を指定しているので、抜き出しをチェックする元のデータが、最初から8文字ずれるんで、次のようになっているのと同じことになります。
カレー1</li>
<li>ハンバーグ1</li>
<li>オムライス1</li>
</ul>
<ul>
<li>カレー2</li>
<li>ハンバーグ2</li>
<li>オムライス2</li>
</ul>カレー1は<li></li>で挟まれてないので、コードを実行すると、ハンバーグ1からのデータが抜き出されます。
[ハンバーグ1, オムライス1, カレー2, ハンバーグ2, オムライス2]
ログに出力する。
各種パラメーターや見つかった文字列のindex値などを取得できます。
.setLog()
function test(){
// HTMLの情報
var html = "<ul>" +
"<li>カレー1</li>" +
"<li>ハンバーグ1</li>" +
"<li>オムライス1</li>" +
"</ul>" +
"<ul>" +
"<li>カレー2</li>" +
"<li>ハンバーグ2</li>" +
"<li>オムライス2</li>" +
"</ul>"
// Parserオブジェクトの生成
var parser = Parser.data(html)
// 抜き出し
var res = parser.setLog().from("<li>").to("</li>").build()
// ログに出力
Logger.log(res)
}これを実行すると、次のような情報がログに出力されます。
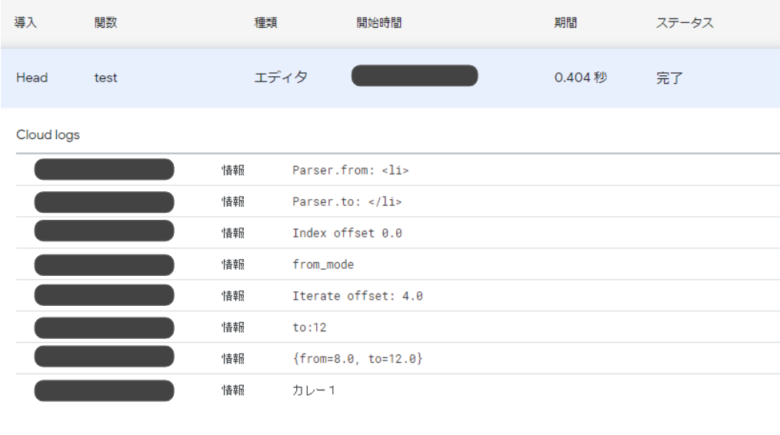
engageのデータを取得する
それでは、実際のサイトからデータを抽出してみましょう。
Parserオブジェクトの生成までは大丈夫ですね?次のコードになります。
function test(){
// WEBサイトのURLを指定
var url = "https://en-gage.net/search/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセスして、文字列情報として取得する
var html= UrlFetchApp.fetch(url).getContentText()
// Parserオブジェクトの生成
var parser = Parser.data(html)
}ここから抽出をしていきます。
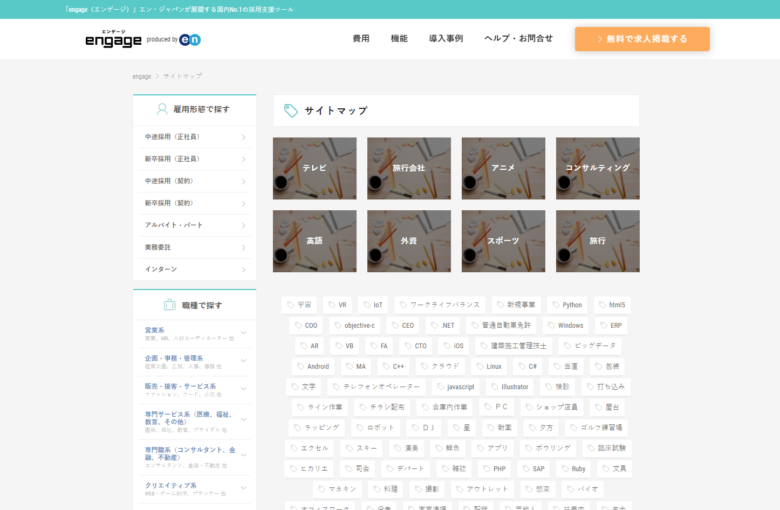
https://en-gage.net/search/のHTMLの構造を別投稿でメモってありますので、そちらで構造は確認してください。(執筆時点での情報です)

また、HTMLの構造を確認する場合は、ブラウザに付属しているデベロッパーツール(F12押すと出てくるよ)か、ブラウザ上で右クリックをして「ページのソースを表示」を使います。
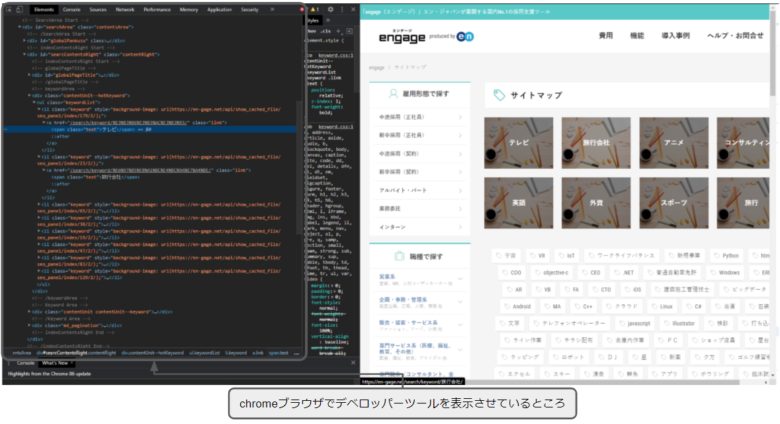
次の図で囲われている、「テレビ」「旅行会社」などのテキストデータの一覧を取得することを考えたいと思います。
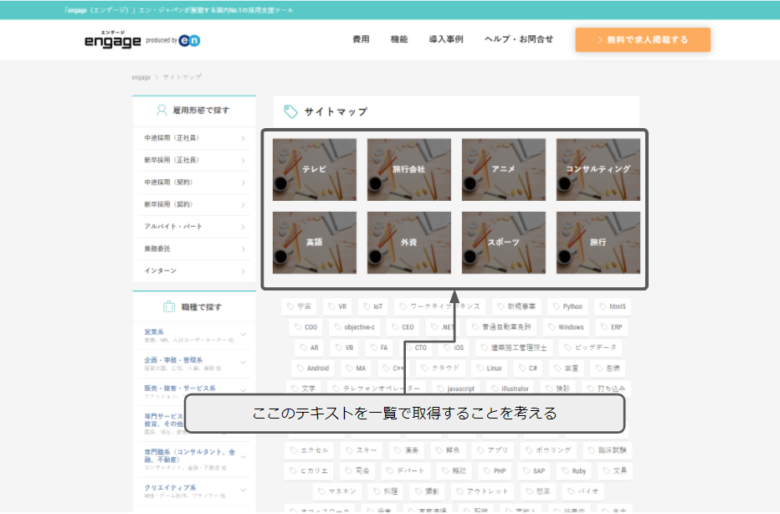
HTMLのソースで調べると、次の部分にあることが分かります。
*** 省略 ***
<!-- keywordArea -->
<div class="contentUnit--hotKeyword">
<ul class="keywordList">
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/179/2/);"><a href="/search/keyword/%E3%83%86%E3%83%AC%E3%83%93/" class="link"><span class="text">テレビ</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/23/2/);"><a href="/search/keyword/%E6%97%85%E8%A1%8C%E4%BC%9A%E7%A4%BE/" class="link"><span class="text">旅行会社</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/65/2/);"><a href="/search/keyword/%E3%82%A2%E3%83%8B%E3%83%A1/" class="link"><span class="text">アニメ</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/38/2/);"><a href="/search/keyword/%E3%82%B3%E3%83%B3%E3%82%B5%E3%83%AB%E3%83%86%E3%82%A3%E3%83%B3%E3%82%B0/" class="link"><span class="text">コンサルティング</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/19/2/);"><a href="/search/keyword/%E8%8B%B1%E8%AA%9E/" class="link"><span class="text">英語</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/47/2/);"><a href="/search/keyword/%E5%A4%96%E8%B3%87/" class="link"><span class="text">外資</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/83/2/);"><a href="/search/keyword/%E3%82%B9%E3%83%9D%E3%83%BC%E3%83%84/" class="link"><span class="text">スポーツ</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/129/2/);"><a href="/search/keyword/%E6%97%85%E8%A1%8C/" class="link"><span class="text">旅行</span></a></li>
</ul>
</div>
<!-- /keywordArea --
*** 省略 ***必要な情報は、<span class=”text”> ~ </span>で囲われていそうですね。
上手く取り出せるかやってみましょう。
function test(){
// WEBサイトのURLを指定
var url = "https://en-gage.net/search/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセスして、文字列情報として取得する
var html= UrlFetchApp.fetch(url).getContentText()
// Parserオブジェクトの生成
var parser = Parser.data(html)
// 抜き出し
var res = parser.from('<span class="text">').to('</span>').iterate()
// ログに出力
Logger.log(res)
}実行すると、次の結果がログに出力されます。
[テレビ, 旅行会社, アニメ, コンサルティング, 英語, 外資, スポーツ, 旅行, 1, 2, 3, 次へ, 営業、MR、人材コーディネーター 他, 経営企画、広報、人事、事務 他, ファッション、フード、小売 他, 医療、福祉、教育、ブライダル 他, コンサルタント、金融・不動産 他, WEB・ゲーム制作、プランナー 他, アプリ開発、ITコンサル、PM 他, 回路・制御設計、研究他, 建築・設備設計、施工管理 他, 研究、生産管理、品質管理他, 警備、清掃、ドライバー他, 公務員、警察・消防、学校法人他, 電気、機械、自動車、医療機器他, 化学、鉄鋼、医薬品、日用品他, 飲食、教育、アミューズメント 他, シンクタンク、マーケティング他, 建設、土木、不動産他, 鉄道、空輸、海運、物流、倉庫他, 総合商社、食料品、アパレル、インテリア 他, 銀行、証券、生保、クレジット他, 放送、出版、広告、ゲーム、デザイン 他, 百貨店、コンビニ、ドラックストア 他, ソフトウェア、インターネット他, 電気、ガス、インフラ、官公庁他, 上場企業、官公庁・学校関連他, 試用期間あり、正社員登用あり他, 英語・外国語を使う仕事他, 10名以上の大量募集他, 年間休日120日以上、夏季休暇他, 営業、MR、人材コーディネーター 他, 経営企画、広報、人事、事務 他, ファッション、フード、小売 他, 医療、福祉、教育、ブライダル 他, コンサルタント、金融・不動産 他, WEB・ゲーム制作、プランナー 他, アプリ開発、ITコンサル、PM 他, 回路・制御設計、研究他, 建築・設備設計、施工管理 他, 研究、生産管理、品質管理他, 警備、清掃、ドライバー他, 公務員、警察・消防、学校法人他, 電気、機械、自動車、医療機器他, 化学、鉄鋼、医薬品、日用品他, 飲食、教育、アミューズメント 他, シンクタンク、マーケティング他, 建設、土木、不動産他, 鉄道、空輸、海運、物流、倉庫他, 総合商社、食料品、アパレル、インテリア 他, 銀行、証券、生保、クレジット他, 放送、出版、広告、ゲーム、デザイン 他, 百貨店、コンビニ、ドラックストア 他, ソフトウェア、インターネット他, 電気、ガス、インフラ、官公庁他, 上場企業、官公庁・学校関連他, 試用期間あり、正社員登用あり他, 英語・外国語を使う仕事他, 10名以上の大量募集他, 年間休日120日以上、夏季休暇他, engage search, または, engage search, ログインに失敗しました。ログインID、パスワードをご確認のうえ、再度ログインください。, または]
いらないやつまで入っちゃってますね。。。
取り出したいデータだけにする場合は、HTMLのタグを辿っていって、何段階かに分けて抽出することで、特定のデータに絞り込めるときがあります。
*** 省略 ***
<!-- keywordArea -->
<div class="contentUnit--hotKeyword">
<ul class="keywordList">
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/179/2/);"><a href="/search/keyword/%E3%83%86%E3%83%AC%E3%83%93/" class="link"><span class="text">テレビ</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/23/2/);"><a href="/search/keyword/%E6%97%85%E8%A1%8C%E4%BC%9A%E7%A4%BE/" class="link"><span class="text">旅行会社</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/65/2/);"><a href="/search/keyword/%E3%82%A2%E3%83%8B%E3%83%A1/" class="link"><span class="text">アニメ</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/38/2/);"><a href="/search/keyword/%E3%82%B3%E3%83%B3%E3%82%B5%E3%83%AB%E3%83%86%E3%82%A3%E3%83%B3%E3%82%B0/" class="link"><span class="text">コンサルティング</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/19/2/);"><a href="/search/keyword/%E8%8B%B1%E8%AA%9E/" class="link"><span class="text">英語</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/47/2/);"><a href="/search/keyword/%E5%A4%96%E8%B3%87/" class="link"><span class="text">外資</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/83/2/);"><a href="/search/keyword/%E3%82%B9%E3%83%9D%E3%83%BC%E3%83%84/" class="link"><span class="text">スポーツ</span></a></li>
<li class="keyword" style="background-image: url(https://en-gage.net/api/show_cached_file/seo_panel/index/129/2/);"><a href="/search/keyword/%E6%97%85%E8%A1%8C/" class="link"><span class="text">旅行</span></a></li>
</ul>
</div>
<!-- /keywordArea --
*** 省略 ***例えば、この例でいくと、<ul class=”keywordList”>~</ul>で抜き出してから、その中の<span class=”text”> ~ </span>で囲われている部分を抽出するといった感じで、2段階に分けてみます。
コードは次のようになります。
function test(){
// WEBサイトのURLを指定
var url = "https://en-gage.net/search/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセスして、文字列情報として取得する
var html= UrlFetchApp.fetch(url).getContentText()
// Parserオブジェクトの生成(1段階目)
var parser = Parser.data(html)
// 抜き出し(1段階目)
var res = parser.from('<ul class="keywordList">').to('</ul>').build()
// Parserオブジェクトの生成(2段階目)
// ※1段階目で抜き出したHTML文字列でもう一回Parserオブジェクトをつくる
var parser2 = Parser.data(res)
// 抜き出し(2段階目)
var res2 = parser2.from('<span class="text">').to('</span>').iterate()
// ログに出力
Logger.log(res)
}実行して、ログを確認すると、
[テレビ, 旅行会社, アニメ, コンサルティング, 英語, 外資, スポーツ, 旅行]
必要な情報だけ取得することが出来ましたね。
このようにスクレイピングするときは、HTMLの構造とにらめっこしながら、Parserクラスのメソッドを駆使して特定の情報にたどり着けるように頑張ります笑
スプレッドシートに書き出す
これは問題ないかと思いますが、次のコードで実装しましょう!
先程のコードに追加します。
function test(){
// WEBサイトのURLを指定
var url = "https://en-gage.net/search/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセスして、文字列情報として取得する
var html= UrlFetchApp.fetch(url).getContentText()
// Parserオブジェクトの生成(1段階目)
var parser = Parser.data(html)
// 抜き出し(1段階目)
var res = parser.from('<ul class="keywordList">').to('</ul>').build()
// Parserオブジェクトの生成(2段階目)
// ※1段階目で抜き出したHTML文字列でもう一回Parserオブジェクトをつくる
var parser2 = Parser.data(res)
// 抜き出し(2段階目)
var res2 = parser2.from('<span class="text">').to('</span>').iterate()
// ログに出力
Logger.log(res2)
// スプレッドシートに書き出し
var spreadsheet = SpreadsheetApp.getActiveSpreadsheet() //スプレッドシートの取得
var sheet = spreadsheet.insertSheet("newSheet") // 新しいシートを「newSheet」の名前で追加
// セルに順番に書き出し
for(var i=1; i<=res2.length; i++){
sheet.getRange(i,1).setValue(res2[i])
}
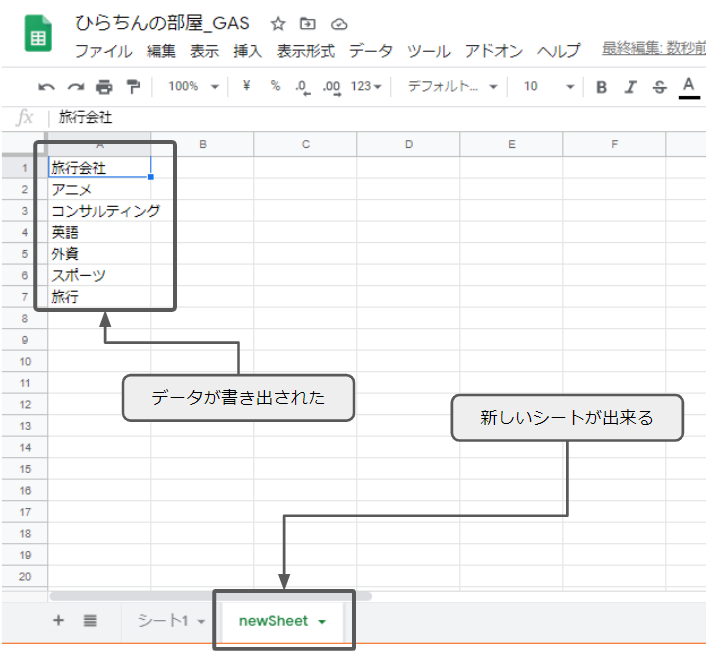
}実行すると、新しく「newSheet」が出来上がり、A1セルから順番にres2の配列の要素が書き出されます。
まとめ
「WEBサイトの情報をGASで取得する1」でした。データ収集は、単一ページなことは少ないと思いますし、定期的に自動で実行したいことが多いかと思いますので、「WEBサイトの情報をGASで取得する2」として、ページ遷移やトリガー設定についても紹介したいと思います!
コメント