はじめに
Googleスプレッドシートで正規表現が使える関数!
以前に、スプレッドシートのクエリ関数で正規表現を使う方法を紹介させていただきました。
実はクエリ関数だけでなく、スプレッドシート上の他の関数でも、正規表現を使えもものがあります!EXCELではVBAでユーザー定義関数作らないと実現出来ない正規表現!スプレッドシートなら手軽に使えちゃいます!
どうせスプレッドシート使うなら、EXCELではできないことを覚えた方が良いですよね!
ということで、今回は正規表現を使えるスプレッドシート関数を紹介させていただきます!
正規表現
まずは正規表現についてです。
「正規表現」って知ってますか?多分プログラミングをする人以外には普段接することがない言葉ですよね。スプレッドシートやEXCELなどをよく使っているかたでもあまり目にすることは無いんじゃないかと思います。
プログラミングをする人にはおなじみの言葉で、この「正規表現」というものだけで沢山の本が出ているくらいです。
という感じで書くと、難しそう。。。って感じますね(笑)
でも安心して下さい。この正規表現というのは基本的なことはそんなに難しく有りません。もちろん極めようと思えば大変な努力が必要だと思いますが、「スプレッドシートでちょろっと便利に使おう!」くらいのノリで使う分には、一番最初のサキッちょの分かる範疇をペロッとしたくらいでも「へーめっちゃ良いやん!」的な間隔になれると思います^_^
正規表現とは
前置きが長くなりましたが、正規表現とは簡単に言ってしまうと、
です。
分かりにくいと思うので、早速ですがよく使われる正規表現の記号の一覧です。
よく使われる「正規表現」の記号
| 記号 | 意味 | 正規表現の例 | マッチする文字列の例 |
|---|---|---|---|
| . | 任意の1文字 | . | a , b, c なんでも |
| ? | 0回または1回の出現 | ab?cd |
acd → 0回 abcd → 1回 |
| * | 0回以上の繰り返しの出現 | ab*cd |
acd → 0回 abcd → 1回 abbcd → 2回 abbbcd → 3回 abbbb・・・cd → 4回以上何回でも |
| + | 1回以上の繰り返しの出現 | ab+cd |
abcd → 1回 abbcd → 2回 abbbcd → 3回 abbbb・・・cd → 4回以上何回でも |
| {n} | n回の繰り返しの出現 | ab{3}cd | abbbcd → 3回 |
| {n,} | n回以上の繰り返しの出現 | ab{3,}cd |
abbbcd → 3回 abbbbcd → 4回 abbbbbcd → 5回 abbbbbb・・・cd → 5回以上何回でも |
| {m,n} | n回以上m回以下の繰り返しの出現 | ab{3,4}cd |
abbbcd → 3回 abbbbcd → 4回 |
| ^ | 文字列の先頭 | ^abcd | abcd~ → abcで始まる |
| $ | 文字列の末尾 | abcd$ | ~abcd → abcdで終わる |
| | | |の左側の文字列もしくは、|の右側の文字列 | a(b|c)d |
abd acd |
| \w | アルファベット、アンダーバー、数字 | ab\wcd |
abgcd ab_cd ab9cd ab[a-zA-Z_0-9]cdと同じ |
| \W | アルファベット、アンダーバー、数字以外の文字 | ab\Wcd |
abあcd ab青cd ab[^a-zA-Z_0-9]cdと同じ |
| \s | 空白文字(半角スペース,タブ,改行,キャリッジリターン) | ab\scd |
ab cd ※半角スペース |
| \S | 空白文字以外 | ab\Scd |
abgcd ab9cd |
| \d | 半角数字(0~9) | ab\dcd |
ab8cd ab5cd |
| \D | 半角数字以外 | ab\Dcd |
abmcd abKcd |
| [~] | ~のいずれかの1文字 | ab[cde]fg |
abcfg abdfg abefg |
| [^~] | ~のいずれの1文字にも一致しない | ab[^cde]fg |
abafg abbfg abffg ab1fg |
※他にもたくさんありますので興味のある方はググったり本を買ったりして勉強して下さい!
このような、記号を組み合わせて文字列のパターンを作成し、そのパターンにマッチした文字列を検索するために使います。
要するに、「超便利なあいまい検索」って感じですね^_^
正規表現が使える関数
それではこいつを利用出来るスプレッドシート関数について紹介していきます!
【サンプル】都道府県の県庁所在地の住所一覧
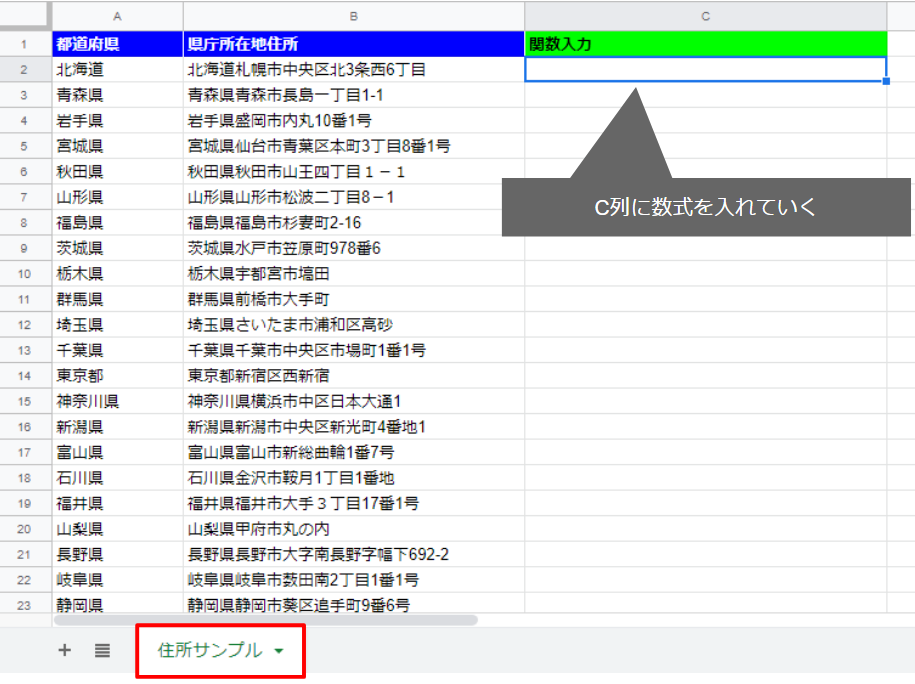
このサンプルで、C列に正規表現を使える関数を入力して試していきます!
REGEXEXTRACT関数
まずは単純に正規表現を使って、文字列を抜き出す関数「REGEXEXTRACT関数」です。
構文
=REGEXEXTRACT(“文字列”,”正規表現”)
引数に指定した正規表現にマッチした文字列を抜き出す関数です。
次の数式をC2セルに入力して、B2セルの住所から都道府県を抜き出します。
=REGEXEXTRACT(B2,”..+?[都道府県]”)
第1引数には、抜き出す対象の文字列なのでB2、第2引数に正規表現を指定します。
第2引数の「正規表現」の部分だけ抜き出すと。
..+?[都道府県]
ややこしいですが、説明します。
「.」ドットは任意の1文字、「..」ドットが2個続いているので任意の2文字ですね。
「+」プラスは1回以上の繰り返しなので、直前の「.」が1回以上繰り返すことになります。
ここまでで言うと、「..+」は2文字かそれ以上の任意の文字ということになります。
「?」ハテナは、0回か1回の出現ということになりますので、直前の「+」プラスは出現しないか、1回だけ出現することになります。
つまり、「..+?」で、2文字か3文字ということが表現できます。
[都道府県]は、「都」か「道」か「府」か「県」かのいずれか1文字とマッチする意味なので、「..+?[都道府県]」とすれば、都道府県が抜き出せることになります。
実際に入力してみます。
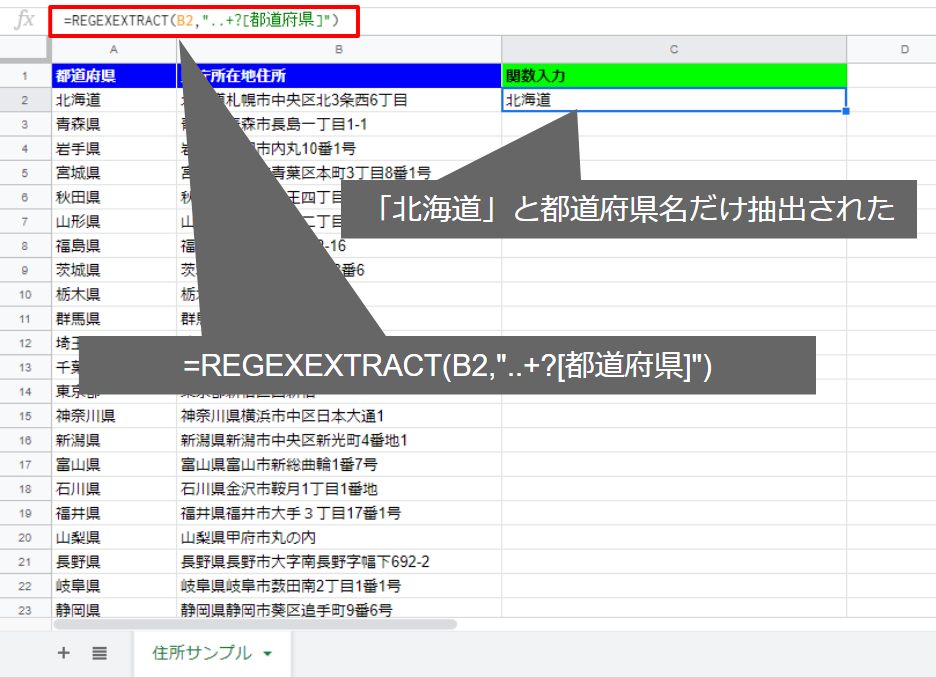
下まで数式をコピーします。
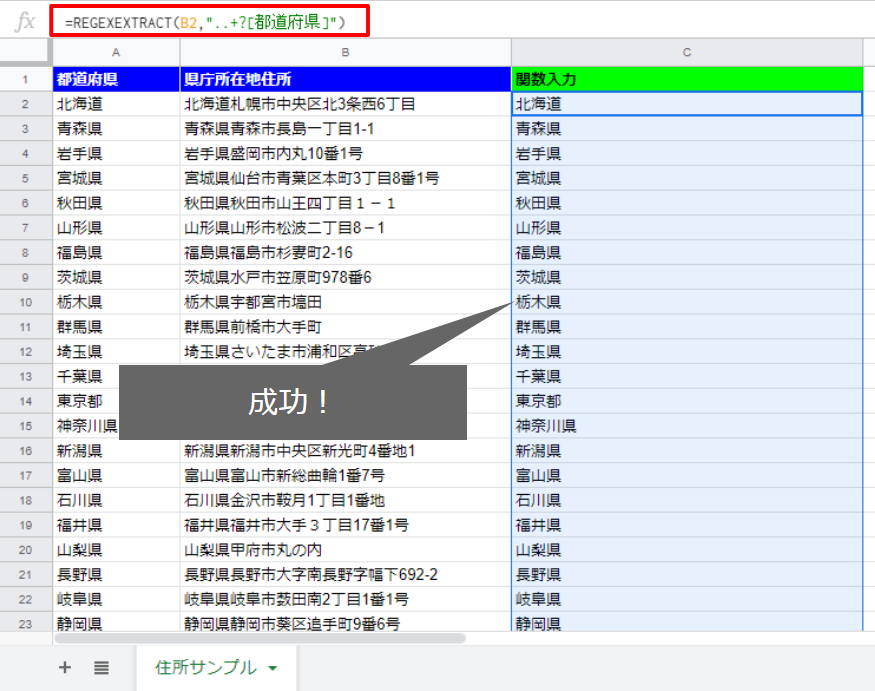
図のように、きちんと都道府県が抜き出せていることが分かります(^^)
「都道府県」の抜き出しは通常の関数の組み合わせでも出来るんですが、これでやったらむちゃくちゃ簡単に出来ちゃいます!
REGEXREPLACE関数
続いて、正規表現でマッチした文字列を違う文字列に置換える「REGEXREPLACE関数」です。
構文
=REGEXREPLACE(“文字列”,”正規表現”, “置換文字列”)
引数に指定した正規表現にマッチした文字列を別の文字列に置き換える
第1引数と第2引数までは先程と同じですね。先程の例で考えると、都道府県を抜き出しましたが、この関数ではその文字列を、第3引数で指定した文字列に置換えてくれます。
先程のサンプルで試してみます。
C2セルの数式を以下の数式に変更して、下までコピペします。
=REGEXREPLACE(B2,”..+?[都道府県]”,”取り替えたよ!”)
正規表現は先程と同じなので、都道府県のあったところの文字列が「取り替えたよ!」に変わるはずです。
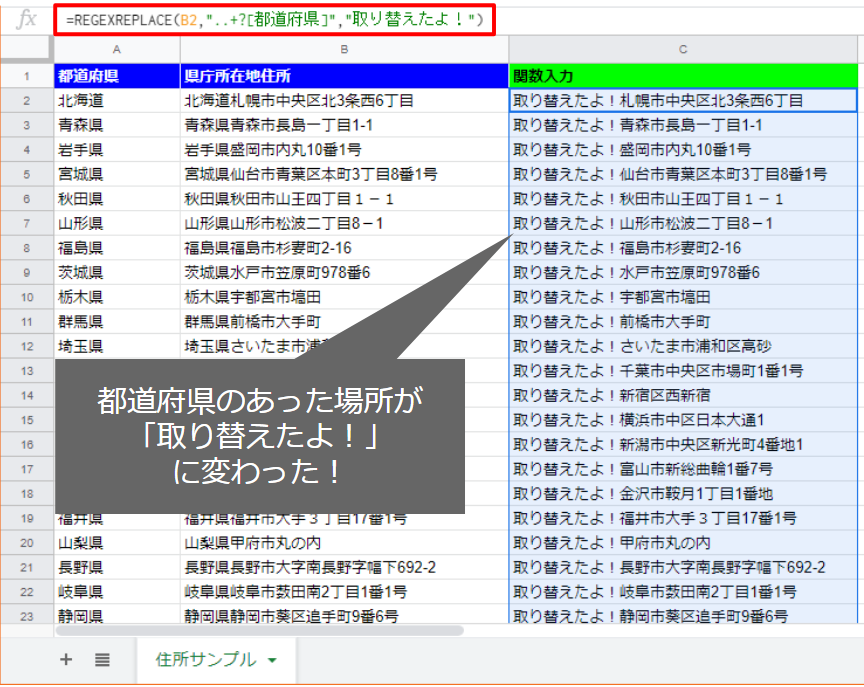
きちんと変わりましたね(^^)
ちなみに、第3引数を「””」ダブルクォーテーション2つで入れると、取り替えた後になにも入れないということができます。つまり「取り除く」です。
都道府県なんかの一覧だと、この「取り除く」処理の方が多いでしょうね。
やってみます。
C2セルを次の数式(第3引数を「””」)に変更して、下までコピペします。
=REGEXREPLACE(B2,”..+?[都道府県]”,””)
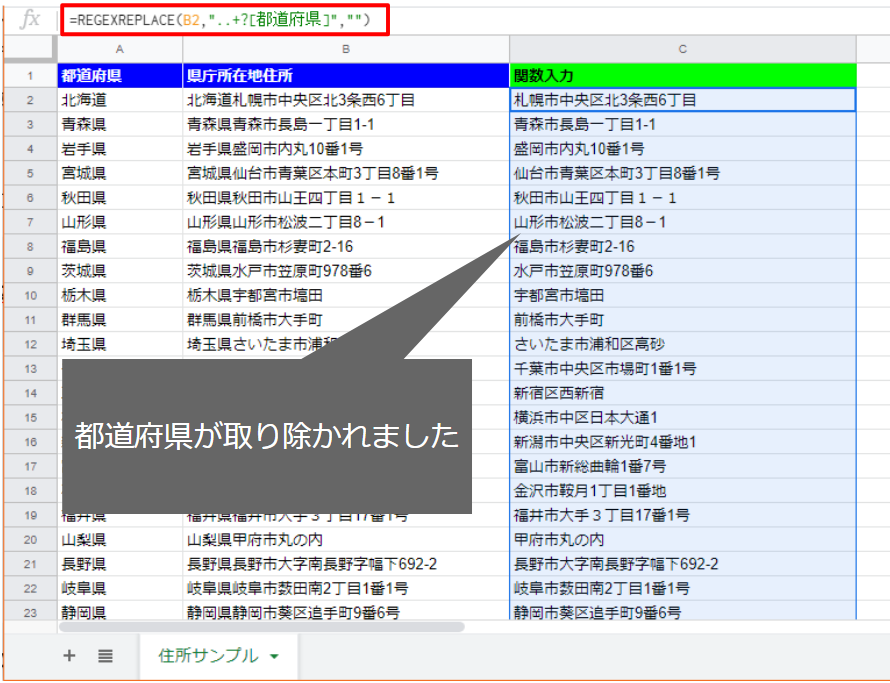
都道府県がきれいに取り除かれましたね(^^)
正規表現でマッチした文字列を一気に取り除いたりなど、非常に便利に使えます!
REGEXMATCH関数
最後に、「REGEXMATCH関数」です。引数で指定した、パターンにマッチするかどうかを判定することができます。
構文
=REGEXMATCH(“文字列”,”正規表現”)
引数に指定した正規表現にマッチすれば「True」しなければ「False」を返す
今回は、先程のサンプルに「都道府県」を「北海道道」など2重で入力されてしまった場合のミスを想定して、2個続いているかどうかを判定してみます。
※何個かのデータをミスデータに変更しています。
C2セルに以下の数式を入力して、下までコピーして下さい。
=REGEXMATCH(B2,”[都道府県]{2,}”)
第2引数の「正規表現」の部分だけ抜き出すと。
[都道府県]{2,}
{2,}は2回以上の繰り返しにマッチしますので、その直前の文字列「都」「道」「府」「県」のいずれかが2回連続以上で出現しているという意味ですね。
マッチしたら「TRUE」になるので、「TRUE」はミスってる!(T_T)ってことになります。
それでは、見てみます。
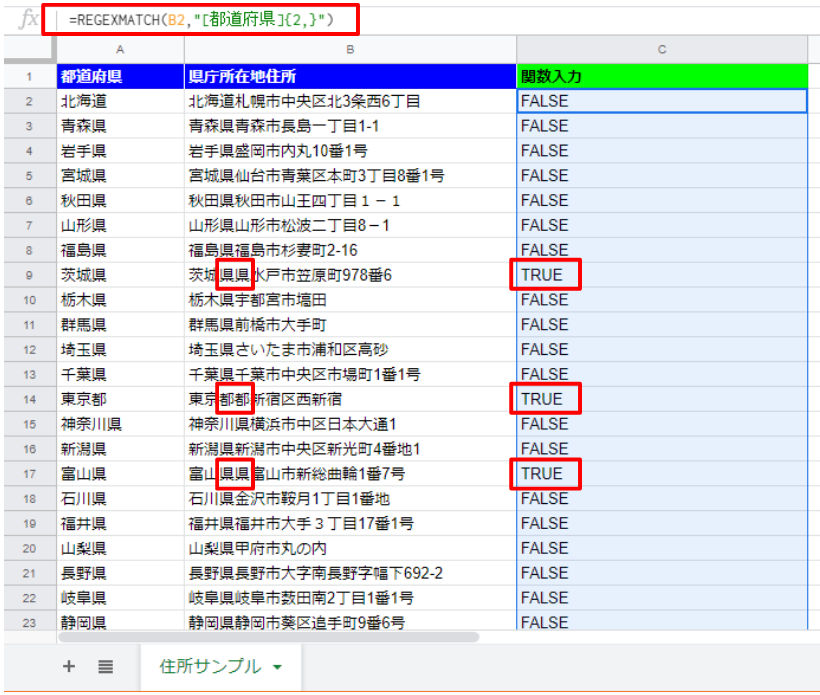
「TRUE」になった元データを見ると、”都”や”県”が連続で入ってしまっていることが分かります(^^)
こんな風に、ミスチェックの判定につかったり、IFやSUMIFなど条件指定の関数と組み合わせることで、いろんなことができそうですね!
まとめ
以上、正規表現を使える関数を紹介しました!
良いでしょ?^_^
コメント