WEBサイトの情報をGASで取得する2
前回、以下の記事でGASを使ってWEBサイトの情報を収集するための基礎を紹介しました。
単一ページをGASで取得する場合の、基本的なプログラムの流れとParserライブラリの利用方法は理解頂けたと思います。
ただ、WEBサイトの情報を取得したい場合というのは、サイトの複数ページだったり、一定条件で検索を掛けた結果を取得したい場合がほとんどかと思います。
今回は、もう一歩進んで、検索結果を表示させたり、ページを遷移させたりするところを紹介したいと思います!
プログラムの流れ
以下は、前回の記事のプログラムの流れです。
- 情報を取得したいWEBサイトのURLを確認する
- UrlFetchAppクラスを使って、GASからWEBサイトの情報にアクセスする
- 返ってきた情報から必要な情報を抜き出す
- スプレッドシートに書き出す
これは単一ページでのプログラムの流れでした。
基本はこの流れなのですが、検索結果を表示させて、ページ送りをしていく場合には、プラスアルファの工程が必要になります。
以下が、検索結果を表示させて、最後のページまで進んで情報をとってくるプログラムの流れです。
- 情報を取得したいWEBサイトのURLを確認する
- UrlFetchAppクラスを使って、GASからWEBサイトの検索した状態のURLにアクセスする
- 返ってきた情報から必要な情報を抜き出す
- スプレッドシートに書き出す
- 最後のページかどうか確認する
- 最後のページでない場合→8へ進む
- 最後のページの場合→9へ進む
- 「次のページ」のリンクを取得して、UrlFetchAppクラスを使って次のページにアクセスする。→3に戻る
- 最後のページだった場合プログラムを終了する
それでは、一つずつ行きましょう!
情報を取得したいWEBサイトのURLを確認する
まずは、情報取得したいURLを調べます。これは普通にブラウザでWEBサイトを表示させて、アドレスバーにあるURLを確認します。
「バイトル」という求人情報のサイトできましょう!
アドレスバーにあるURLはこちらです。

こいつをメモっときましょう。
UrlFetchAppクラスを使って、GASからWEBサイトの検索した状態のURLにアクセスする
次に、プログラムからWEBサイトにアクセスさせるのですが、今回は検索条件を指定してその結果を取得したいと思います。
GASプログラムでWEBサイトにアクセスするには、UrlFetchAppクラスを利用するんでしたね。
分からない方は、以下の記事をご覧ください。
GASからプログラムにアクセスする場合は、fetchメソッドを使います。
UrlFetchApp.fetch(url)
1.でメモっといた「https://www.baitoru.com/」を引数に指定すると、バイトルのトップページの情報が取得されます。
function test(){
// WEBサイトのURLを指定
var url = "https://www.baitoru.com/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセス
var res = UrlFetchApp.fetch(url).getContentText()
// 返り値resをログに表示
Logger.log(res)
}検索結果を表示させるにはどうすればいいでしょうか?
一度、ブラウザで自力で検索してみましょう!
検索条件は、
- 関西
- 兵庫県
- エリア
- 加古郡
でいきましょうか。
検索結果が表示されます。
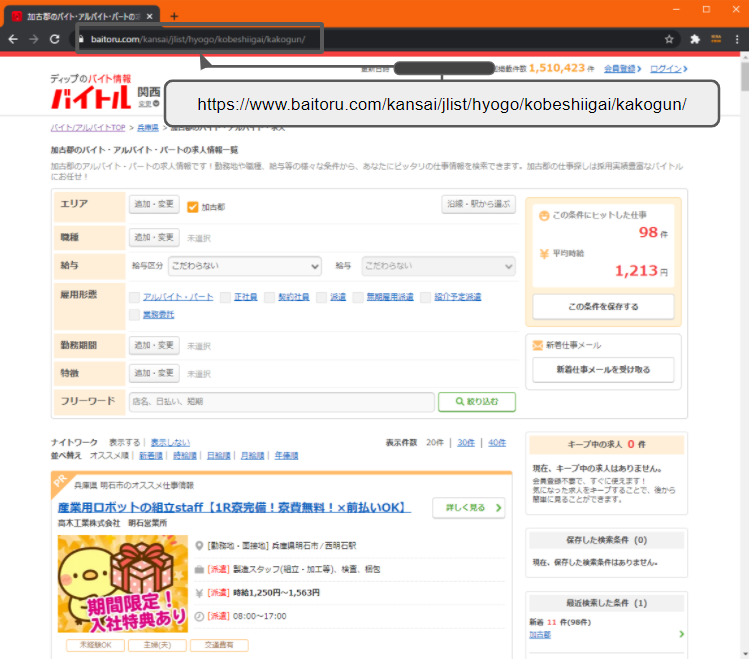
アドレスバーに注目してください。

「https://www.baitoru.com/」に続きが出て来ましたね!
このような検索した結果のアドレスを、UrlFetchApp.fetch(url)の引数urlに渡してあげることで、検索結果画面の情報を取得することが出来ます。
やってみましょう。
function test(){
// WEBサイトのURLを指定
var url = "https://www.baitoru.com/kansai/jlist/hyogo/kobeshiigai/kakogun/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセス
var res = UrlFetchApp.fetch(url).getContentText()
// 返り値resをログに表示
Logger.log(res)
}表示されたログを確認すると、次の図のように検索された後のWEBページのHTMLの情報が取れていることが分かります。
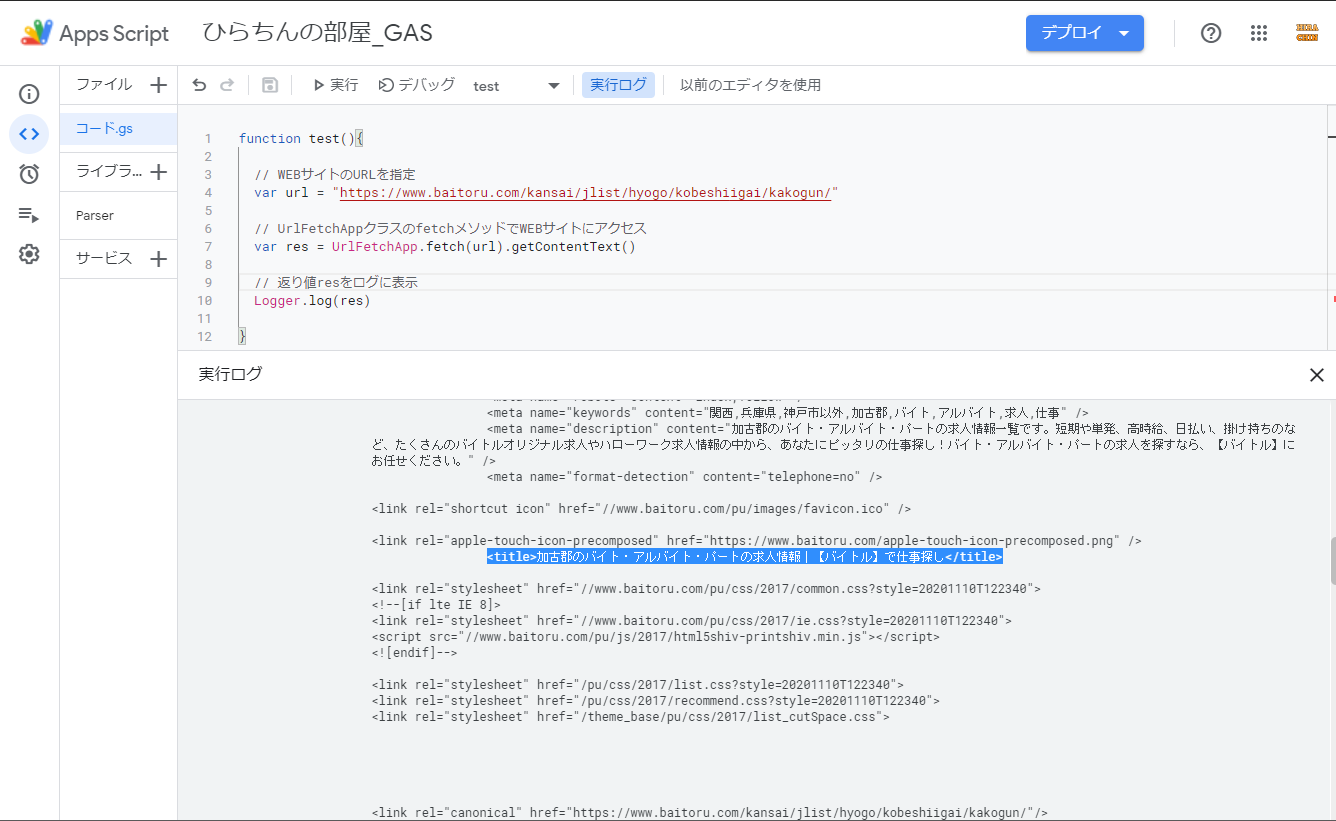
関係ないですが、スクリプトエディタが新しくなりましたね(^o^)
サイトのURLが検索項目に対して、どのような構造になっているかが分かれば、URLを組み立てることで、検索自体も自動化出来ますね(^^)
返ってきた情報から必要な情報を抜き出す
2.で返ってきたHTMLの情報から、必要な部分を抜き出してスプレッドシートに書き出します。
Parserライブラリを使った方法を前回も紹介させて頂きましたので、同じ方法でやっていきます。
検索結果画面の一覧から、「社名」と「職種名」を抜き出していきましょう。
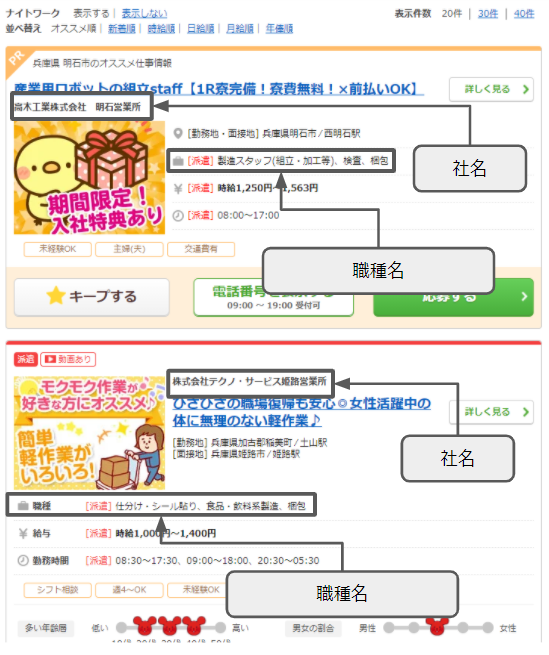
それでは、HTMLのソースを眺めて社名と職種名のタグを探しましょう。
よく見ると、図1の各案件には、左上に「PR」ってなっているものと、そうでないものの2種類存在することが分かります。
ホントは両方取得しに行きたいんですが、両方にすると話が複雑になるので、分かりやすいように「PR」が付いて無い方の情報だけ取得していきます。
ソースを見て、HTMLの構造を確認しましょう。
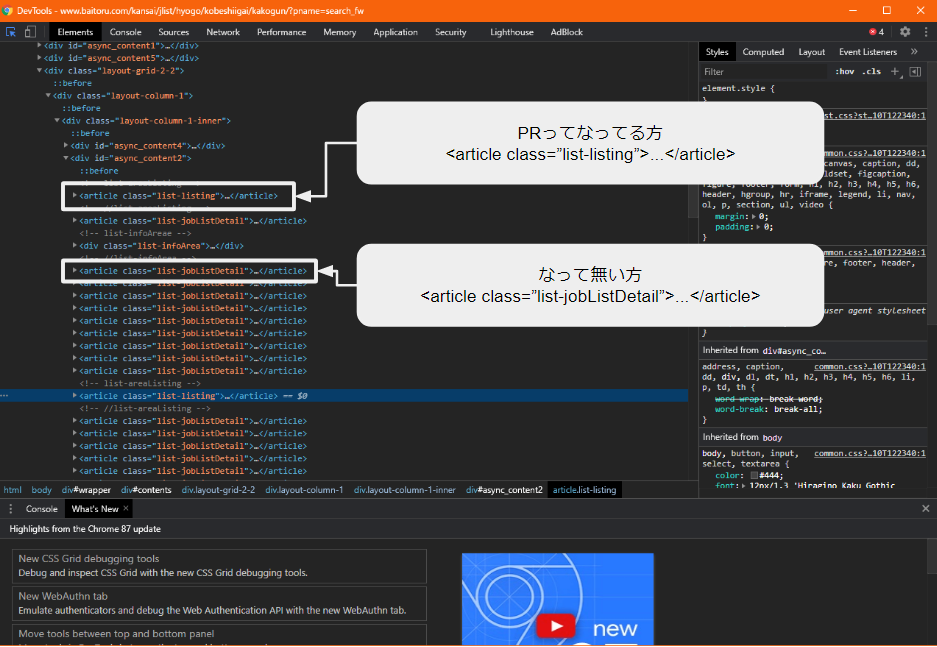
PRってなってる方は、
<article class=”list-listing”>…</article>
で囲まれてるっぽいですね。
PRってなって無い方は、
<article class=”list-jobListDetail”>…</article>
これで囲まれてるっぽいですね。
「PR」の付いて無い方のタグで情報を取り出してみましょう。
function test(){
// WEBサイトのURLを指定
var url = "https://www.baitoru.com/kansai/jlist/hyogo/kobeshiigai/kakogun/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセス
var html = UrlFetchApp.fetch(url).getContentText()
// Parserオブジェクトの生成(1段階目)
var parser = Parser.data(html)
// 抜き出し(1段階目) ※案件ボックスの中身を配列で取得
var res = parser.from('<article class="list-jobListDetail">').to('</article>').iterate()
// ログに出力(配列の中身を1つずつ取り出す)
for(var i=0;i<res.length;i++){
var tmp = res[i]
Logger.log('No:'+ (i+1)) //これは後でログ見やすくするために付けてる
Logger.log(tmp) //ここで中身を書き出してる
}
}実行してログを確認してみます。
ちょっと長いですが、ログに書き出された一つの要素が次です。一つの案件ボックスの情報が取れていることが分かります。
<div class="pattern-1">
<div class="bg01" id="link_job_detail_pc_jlist_all_p_20_20">
<div class="bg02">
<div class="pt01">
<div class="pt01a">
<ul class="ul01">
<li>派遣</li>
<li>社員登用あり</li>
<li class="li01">動画あり</li>
</ul>
<ul class="ul02">
</ul>
</div>
<div class="pt01b">
<p>
<li class="li02"><span>Happyボーナス<em> 2,000</em>円</span></li>
</p>
</div>
</div>
<div class="pt02">
<div class="pt02a">
<p><img src="/pu/images/spacer.gif" alt=""
data-replaceimage="//image-cdn.baitoru.com/images_job_BS/130242/W_copy_201030_001.jpg?width=200&height=150&fit=bounds"
height="150" width="200"></p>
</div>
<div class="pt02b">
<p>日研トータルソーシング株式会社 メディカルケア事業部神戸オフィス</p>
<ul class="ul01">
<li class="li01">
<h3><a href="/kansai/jlist/hyogo/kobeshiigai/kakogun/job49585856/"><span>オープニング募集!!おばあちゃんとお散歩♪これも仕事のひとつ★<img
src="/pu/images/jobcount.gif?tab=all&officecode=130242&kyotencode=5776042&jobcode=49585856&type=small"
width="1" height="1"></span></a></h3>
</li>
<li class="li02"><em class="color05">詳しく見る</em></li>
</ul>
<ul class="ul02">
<li>
[勤務地] 兵庫県加古郡播磨町 ⁄ <span>播磨町駅</span> </li>
</ul>
</div>
</div>
<div class="pt03">
<dl>
<dt>職種</dt>
<dd>
<ul>
<li>
<span>[派遣]</span>①②施設内介護・看護、介護福祉士・社会福祉士、デイサービス
<span></span>
<span></span>
</li>
</ul>
</dd>
</dl>
<dl>
<dt>給与</dt>
<dd>
<ul>
<li>
<span>[派遣]</span><em>①時給1,250円~1,350円、②時給1,200円~</em>
</li>
</ul>
</dd>
</dl>
<dl>
<dt>勤務時間</dt>
<dd>
<ul>
<li>
<span>[派遣]</span>①②07:00~16:00、08:30~17:30、10:00~19:00
<span></span>
<span></span>
</li>
</ul>
</dd>
</dl>
</div>
<div class="pt04">
<ul>
<li><em>シフト相談</em></li>
<li><em>短期</em></li>
<li><em>週2・3〜OK</em></li>
<li><em>週4〜OK</em></li>
<li><em>週払い</em></li>
<li><em>未経験OK</em></li>
<li><em>主婦(夫)</em></li>
<li><em>ミドル</em></li>
<li><em>シニア</em></li>
<li><em>交通費有</em></li>
</ul>
</div>
<div class="pt05">
<dl class="dl01">
<dt><span>多い年齢層</span></dt>
<dd>
<ul class="ul01">
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30"
alt="10代">10代</span></li>
<li class="on"><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30"
alt="20代">20代</span></li>
<li class="on"><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30"
alt="30代">30代</span></li>
<li class="on"><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30"
alt="40代">40代</span></li>
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30"
alt="50代">50代</span></li>
</ul>
<ul class="ul02">
<li class="li01">低い</li>
<li class="li02">高い</li>
</ul>
</dd>
</dl>
<dl class="dl02">
<dt><span>男女の割合</span></dt>
<dd>
<ul class="ul01">
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30" alt=""></span></li>
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30" alt=""></span></li>
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30" alt=""></span></li>
<li class="on"><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30"
alt=""></span></li>
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30" alt=""></span></li>
</ul>
<ul class="ul02">
<li class="li01">男性</li>
<li class="li02">女性</li>
</ul>
</dd>
</dl>
<dl class="dl03">
<dt><span>仕事の仕方</span></dt>
<dd>
<ul class="ul01">
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30" alt=""></span></li>
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30" alt=""></span></li>
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30" alt=""></span></li>
<li class="on"><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30"
alt=""></span></li>
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30" alt=""></span></li>
</ul>
<ul class="ul02">
<li class="li01">一人で</li>
<li class="li02">大勢で</li>
</ul>
</dd>
</dl>
<dl class="dl04">
<dt><span>職場の様子</span></dt>
<dd>
<ul class="ul01">
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30" alt=""></span></li>
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30" alt=""></span></li>
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30" alt=""></span></li>
<li class="on"><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30"
alt=""></span></li>
<li><span><img src="/pu/images/2017/bg_005a.png" width="134" height="30" alt=""></span></li>
</ul>
<ul class="ul02">
<li class="li01">しずか</li>
<li class="li02">にぎやか</li>
</ul>
</dd>
</dl>
</div>
<div class="pt07">
<div class="pt07a">
<ul>
<li>
<dl>
<dt>応募バロメーター</dt>
<dd>
<ul>
<li class="on"><span><img src="/pu/images/2017/tx_004a.png" width="1"
height="14" alt=""></span></li>
<li><span><img src="/pu/images/2017/tx_004a.png" width="1" height="14"
alt=""></span></li>
<li><span><img src="/pu/images/2017/tx_004a.png" width="1" height="14"
alt=""></span></li>
<li><span><img src="/pu/images/2017/tx_004a.png" width="1" height="14"
alt=""></span></li>
<li class="li01"><span><img src="/pu/images/2017/tx_004a.png" width="1"
height="14" alt=""></span></li>
</ul>
</dd>
</dl>
</li>
<li>
<p><em>今が狙い目!</em></p>
</li>
</ul>
</div>
<div class="pt07b">
<p>採用予定人数:複数名</p>
</div>
</div>
</div>
</div>
<div class="pt08">
<ul class="js-keepModule js-telModule">
<li class="li01"><a href="javascript:void(0);" class="color03 js-keepBtn"
value="49585856:::日研トータルソーシング株式会社 メディカルケア事業部:::/kansai/jlist/hyogo/kobeshiigai/kakogun/job49585856/::://image-cdn.baitoru.com/images_job_BS/130242/W_copy_201030_001.jpg:::播磨町駅:::3:::1,350:::1,250::::::0:::1"
data-type="normal"><em>キープする</em></a><span
class="balloon js-keepMessage"><em>キープ<span>しました!</span></em></span></li>
<li class="li02">
<a href="javascript:void(0);" class="color05 js-tm-btn" data-job_mgr_no="49585856" data-list_no=""
data-tlname="call1_a" data-free_dial_kbn="1" data-obo_saki="日研トータルソーシング株式会社 メディカルケア事業部 神戸オフィス"
data-tel_obo_time="08:30 ~ 18:30 受付可" data-tel_taio_dt_note="※土日、時間外はWEB応募からお願いします。"
data-job_no="【KB】播磨町【C】_介" data-obo_tel="0120-476-053 " data-asp_flg="" data-media=""
data-affiliate="" data-cti_unique_id="222661607996844" data-syain_aim_flg="0">
電話番号を表示する
<em>08:30 ~ 18:30 受付可</em> </a>
</li>
<li class="li03">
<div id="link_job_entry_pc_jlist_all_22_23">
<a href="https://www.baitoru.com/entry/form/job49585856/" class="color01" rel="nofollow">応募する</a>
</div>
</li>
</ul>
</div>
<div class="pt09">
<p class="p02">仕事No.【KB】播磨町【C】_介</p>
</div>
</div>ここから、更に細かく取得します。
取りたかったのは「社名」と「職種名」でしたね。
どんな構造になているか確認します。
まずは「社名」から。社名があるところの近くのHTMLは次です。
<div class="pt02b">
<p>日研トータルソーシング株式会社 メディカルケア事業部神戸オフィス</p>
<ul class="ul01">
<li class="li01">
<h3><a href="/kansai/jlist/hyogo/kobeshiigai/kakogun/job49585856/">
<span>オープニング募集!!おばあちゃんとお散歩♪これも仕事のひとつ★
<img src="/pu/images/jobcount.gif?tab=all&officecode=130242&kyotencode=5776042&jobcode=49585856&type=small" width="1" height="1">
</span>
</a>
</h3>
</li>
<li class="li02"><em class="color05">詳しく見る</em></li>
</ul>
<ul class="ul02">
<li>
[勤務地] 兵庫県加古郡播磨町 ⁄ <span>播磨町駅</span>
</li>
</ul>
</div>社名は
<p>日研トータルソーシング株式会社 メディカルケア事業部神戸オフィス</p>
この部分ですね。
でもpタグは、ここだけじゃ無くて、他の所でも使っているので、これで取り出しはでき無さそうです。
もう少し、大きな枠組みで見ると、どうやらこの部分は、
<div class=”pt02b”>
****
</div>
に囲われていることが分かります。この囲みの中では、pタグは一つしか無いので、これで取りにいけそうですね。
先程のコードを修正していきます。
function test(){
// WEBサイトのURLを指定
var url = "https://www.baitoru.com/kansai/jlist/hyogo/kobeshiigai/kakogun/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセス
var html = UrlFetchApp.fetch(url).getContentText()
// Parserオブジェクトの生成(1段階目)
var parser = Parser.data(html)
// 抜き出し(1段階目) ※案件ボックスの中身を配列で取得
var res = parser.from('<article class="list-jobListDetail">').to('</article>').iterate()
// ここから修正してる
// 取り出したものを入れるための空の配列の用意
var res2 = []
// 配列(res)の中身を1つずつ取り出す
for(var i=0;i<res.length;i++){
// 取り出した中身で再度、Parserオブジェクトを作る
var p = Parser.data(res[i])
// 抜き出し(2段階目) ※pタグ1つにするためのざっくり抜き出し
var tmp = p.from('<div class="pt02b">').to('</div>').build()
// 抜き出し(3段階目) ※社名の抜き出し
p = Parser.data(tmp) // もう一回Parserオブジェクト作る
tmp = p.from('<p>').to('</p>').build()
// 配列(res2)に格納
res2.push(tmp)
}
// ログに書き出し
for(var i=0;i<res2.length;i++){
var tmp2 = res2[i]
Logger.log('No:'+ (i+1))
Logger.log(tmp2)
}
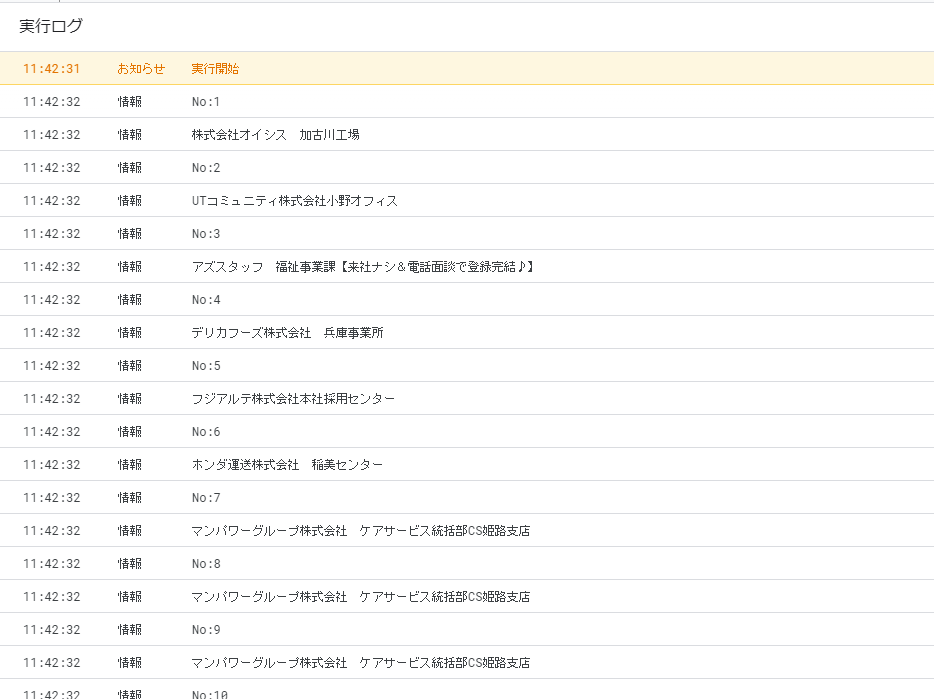
}実行してログを確認します。
こんな感じで社名が取り出せましたね(^o^)
次は職種名ですね。職種名も近くのHTMLを確認してみましょう。
<div class="pt03">
<dl>
<dt>職種</dt>
<dd>
<ul>
<li>
<span>[派遣]</span>①②施設内介護・看護、介護福祉士・社会福祉士、デイサービス
<span></span>
<span></span>
</li>
</ul>
</dd>
</dl>
<dl>
<dt>給与</dt>
<dd>
<ul>
<li>
<span>[派遣]</span><em>①時給1,250円~1,350円、②時給1,200円~</em>
</li>
</ul>
</dd>
</dl>
<dl>
<dt>勤務時間</dt>
<dd>
<ul>
<li>
<span>[派遣]</span>①②07:00~16:00、08:30~17:30、10:00~19:00
<span></span>
<span></span>
</li>
</ul>
</dd>
</dl>
</div>HTMLをよく見ると
<div class=”pt02b”>
****
</div>
の中の一番最初のliタグの中にあります。
<li>
<span>[派遣]</span>①②施設内介護・看護、介護福祉士・社会福祉士、デイサービス
<span></span>
<span></span>
</li>
更に良く見ると、どうやら職種名は、最初の「</span>」と「 」の間にあることが分かります。
これで取ってみましょう。
function test(){
// WEBサイトのURLを指定
var url = "https://www.baitoru.com/kansai/jlist/hyogo/kobeshiigai/kakogun/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセス
var html = UrlFetchApp.fetch(url).getContentText()
// Parserオブジェクトの生成(1段階目)
var parser = Parser.data(html)
// 抜き出し(1段階目) ※案件ボックスの中身を配列で取得
var res = parser.from('<article class="list-jobListDetail">').to('</article>').iterate()
// 取り出したものを入れるための空の配列の用意
var res2 = []
// 配列(res)の中身を1つずつ取り出す
for(var i=0;i<res.length;i++){
// 取り出した中身で再度、Parserオブジェクトを作る
var p = Parser.data(res[i])
// ここから修正してる
/* 社名 */
// 抜き出し(2段階目) ※pタグ1つにするためのざっくり抜き出し
var tmp_syamei = p.from('<div class="pt02b">').to('</div>').build()
// 抜き出し(3段階目) ※社名の抜き出し
var p_syamei = Parser.data(tmp_syamei) // もう一回Parserオブジェクト作る
tmp_syamei = p_syamei.from('<p>').to('</p>').build()
/* 職種名 */
// 抜き出し(2段階目) ※ざっくり抜き出し
var tmp_syokusyu = p.from('<div class="pt03">').to('</div>').build()
// 抜き出し(3段階目) ※職種の抜き出し
var p_syokusyu = Parser.data(tmp_syokusyu) // もう一回Parserオブジェクト作る
tmp_syokusyu = p_syokusyu.from('</span>').to(' ').build()
// 配列(res2)に格納
var tmp = {
"syamei":tmp_syamei,
"syokusyu":tmp_syokusyu
}
res2.push(tmp)
}
// ログに書き出し
for(var i=0;i<res2.length;i++){
Logger.log('No:'+ (i+1))
Logger.log(res2[i].syamei)
Logger.log(res2[i].syokusyu)
}
}実行してログを確認します。
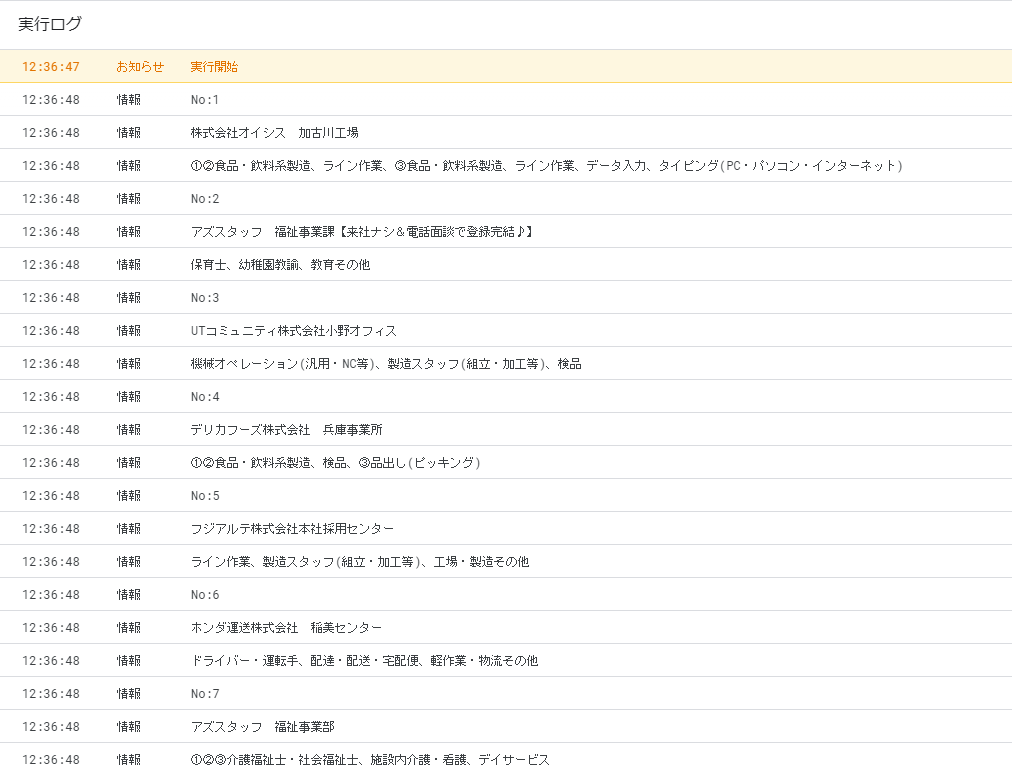
うまく抜き取れました(^o^)
スプレッドシートに書き出す
用意しているスプレッドシートに情報を書き出しましょう。
今回は、output_Spreadsheetという関数を作って、その関数に処理させます。
/**
* 引数に渡したデータをスプレッドシートに書き出す関数
*
* @param {Object[]} メインスクリプトで作成したdata
* Objectの形式は、
* [{"syamei": hoge, "syokusyu": hogehoge},
* {"syamei": hoge2, "syokusyu": hogehoge2}]
*
* @return {} なし
*/
function output_Spreadsheet(data){
// シートの取得(コンテナバインド前提)
var sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName("シート1")
// シートの使用している最終行を取得
var lastRowNum = sheet.getLastRow()
// 順番に書き出し
for(var i=0; i<data.length; i++){
sheet.getRange(lastRowNum+1+i,1).setValue(data[i].syamei)
sheet.getRange(lastRowNum+1+i,2).setValue(data[i].syokusyu)
}
}こいつを、メインスクリプトのログの書き出しの後で呼び出しします。
function test(){
// WEBサイトのURLを指定
var url = "https://www.baitoru.com/kansai/jlist/hyogo/kobeshiigai/kakogun/"
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセス
var html = UrlFetchApp.fetch(url).getContentText()
// Parserオブジェクトの生成(1段階目)
var parser = Parser.data(html)
// 抜き出し(1段階目) ※案件ボックスの中身を配列で取得
var res = parser.from('<article class="list-jobListDetail">').to('</article>').iterate()
// 取り出したものを入れるための空の配列の用意
var res2 = []
// 配列(res)の中身を1つずつ取り出す
for(var i=0;i<res.length;i++){
// 取り出した中身で再度、Parserオブジェクトを作る
var p = Parser.data(res[i])
/* 社名 */
// 抜き出し(2段階目) ※pタグ1つにするためのざっくり抜き出し
var tmp_syamei = p.from('<div class="pt02b">').to('</div>').build()
// 抜き出し(3段階目) ※社名の抜き出し
var p_syamei = Parser.data(tmp_syamei) // もう一回Parserオブジェクト作る
tmp_syamei = p_syamei.from('<p>').to('</p>').build()
/* 職種名 */
// 抜き出し(2段階目) ※ざっくり抜き出し
var tmp_syokusyu = p.from('<div class="pt03">').to('</div>').build()
// 抜き出し(3段階目) ※職種の抜き出し
var p_syokusyu = Parser.data(tmp_syokusyu) // もう一回Parserオブジェクト作る
tmp_syokusyu = p_syokusyu.from('</span>').to(' ').build()
// 配列(res2)に格納
var tmp = {
"syamei":tmp_syamei,
"syokusyu":tmp_syokusyu
}
res2.push(tmp)
}
// ログに書き出し
for(var i=0;i<res2.length;i++){
Logger.log('No:'+ (i+1))
Logger.log(res2[i].syamei)
Logger.log(res2[i].syokusyu)
}
/* ここで呼び出している */
// Spreadsheetに書き出し
output_Spreadsheet(res2)
}
/* ↓に関数定義している */
/**
* 引数に渡したデータをスプレッドシートに書き出す関数
*
* @param {Object[]} メインスクリプトで作成したdata
* Objectの形式は、
* [{"syamei": hoge, "syokusyu": hogehoge},
* {"syamei": hoge2, "syokusyu": hogehoge2}]
*
* @return {} なし
*/
function output_Spreadsheet(data){
// シートの取得(コンテナバインド前提)
var sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName("シート1")
// シートの使用している最終行を取得
var lastRowNum = sheet.getLastRow()
// 順番に書き出し
for(var i=0; i<data.length; i++){
sheet.getRange(lastRowNum+1+i,1).setValue(data[i].syamei)
sheet.getRange(lastRowNum+1+i,2).setValue(data[i].syokusyu)
}
}
実行してスプレッドシートを確認してみましょう。
ちゃんとシートに書き出すことが出来ましたね(^o^)
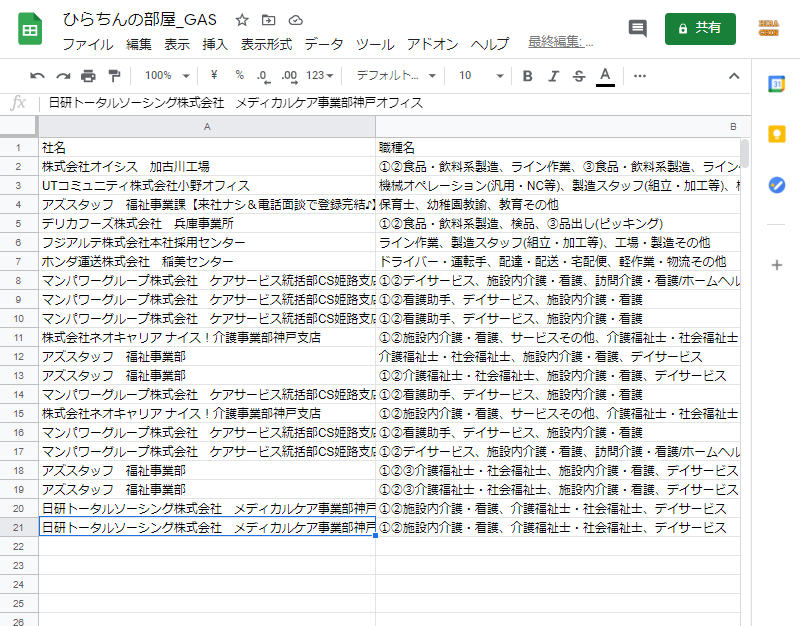
最後のページかどうか確認する~9.最後のページだった場合プログラムを終了する
必要な情報を書き出した後は、検索結果の次のページに進む必要があります。
ここでは、最後のページかどうか確認して、次の挙動を変え、最後だったらプログラムを終了する流れを説明します。
- 情報を取得したいWEBサイトのURLを確認する
- UrlFetchAppクラスを使って、GASからWEBサイトの検索した状態のURLにアクセスする
- 返ってきた情報から必要な情報を抜き出す
- スプレッドシートに書き出す
- 最後のページかどうか確認する
- 最後のページでない場合→8へ進む
- 最後のページの場合→9へ進む
- 「次のページ」のリンクを取得して、UrlFetchAppクラスを使って次のページにアクセスする。→3に戻る
- 最後のページだった場合プログラムを終了する
最後のページかどうかを確認する方法はWEBサイトの作りによって変わって来ますが、基本的には検索結果が複数のページに渡る場合は、だいたい「次のページ」っていうボタンがありますね。
最後のページの場合は、そのボタンがなかったり、リンクが無くなってたりします。
そういった、WEBサイトの作りをよく見て最後のページだと判別出来るものを探しましょう!
バイトルの場合も、下の方にページめくりのボタンがありますね。
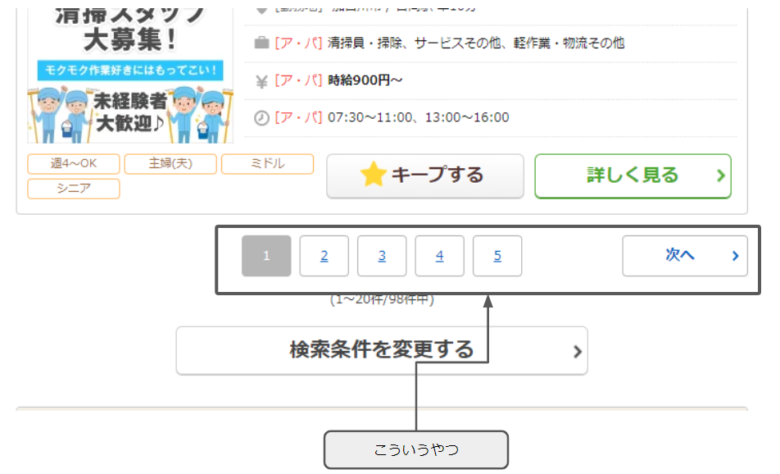
そして、「次へ」のボタンがあるので、ページめくりにはこれが使えそうです。
最後のページまで行ったら、「次へ」ボタンはどうなるでしょうか。
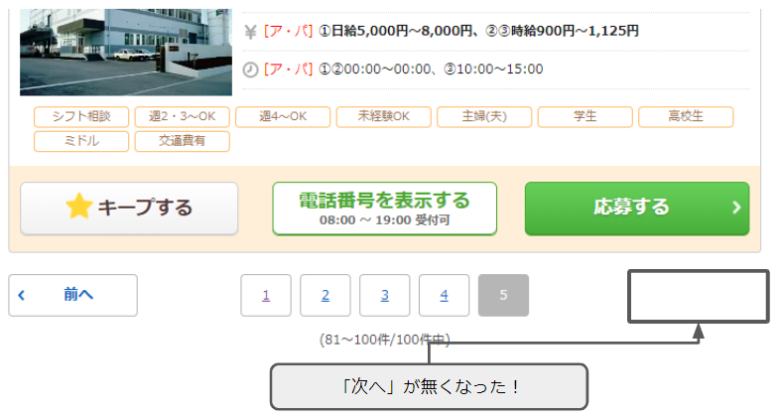
最後のページまで行くと、「次へ」ボタンが無くなりました。
「次へ」ボタンがあるか無いかで、最後のページかどうか判断できそうですね(^o^)
まずは、ここまで作ってきたスクリプトのコードを、次のページに進むように繰り返し処理を入れていきます。
function test(){
// WEBサイトのURLを指定
var url = "https://www.baitoru.com/kansai/jlist/hyogo/kobeshiigai/kakogun/"
// 次へボタンがある間は繰り返し
var tugie = true
while(tugie==true){
// UrlFetchAppクラスのfetchメソッドでWEBサイトにアクセス
var html = UrlFetchApp.fetch(url).getContentText()
// Parserオブジェクトの生成
var parser = Parser.data(html)
/* ここに次へボタンの処理を入れ込んでいる */
// 次へボタンがあるかどうか確認(ある場合は、変数urlを更新、無い場合は変数tugiheをfalseにする)
if(html.match(/次へ/)){
var tmp = parser.from('<li class="next">').to('</li>').build()
var p_next = Parser.data(tmp)
tmp = p_next.from('page').to(',').build()
url = "https://www.baitoru.com/kansai/jlist/hyogo/kobeshiigai/kakogun/" + "page" + tmp + "/"
}else{
tugie=false
}
/* ここまで */
// 抜き出し(1段階目) ※案件ボックスの中身を配列で取得
var res = parser.from('<article class="list-jobListDetail">').to('</article>').iterate()
// 取り出したものを入れるための空の配列の用意
var res2 = []
// 配列(res)の中身を1つずつ取り出す
for(var i=0;i<res.length;i++){
// 取り出した中身で再度、Parserオブジェクトを作る
var p = Parser.data(res[i])
/* 社名 */
// 抜き出し(2段階目) ※pタグ1つにするためのざっくり抜き出し
var tmp_syamei = p.from('<div class="pt02b">').to('</div>').build()
// 抜き出し(3段階目) ※社名の抜き出し
var p_syamei = Parser.data(tmp_syamei) // もう一回Parserオブジェクト作る
tmp_syamei = p_syamei.from('<p>').to('</p>').build()
/* 職種名 */
// 抜き出し(2段階目) ※ざっくり抜き出し
var tmp_syokusyu = p.from('<div class="pt03">').to('</div>').build()
// 抜き出し(3段階目) ※職種の抜き出し
var p_syokusyu = Parser.data(tmp_syokusyu) // もう一回Parserオブジェクト作る
tmp_syokusyu = p_syokusyu.from('</span>').to(' ').build()
// 配列(res2)に格納
var tmp = {
"syamei":tmp_syamei,
"syokusyu":tmp_syokusyu
}
res2.push(tmp)
}
// ログに書き出し
/*
for(var i=0;i<res2.length;i++){
Logger.log('No:'+ (i+1))
Logger.log(res2[i].syamei)
Logger.log(res2[i].syokusyu)
}
*/
/* ここで呼び出している */
// Spreadsheetに書き出し
output_Spreadsheet(res2)
} //whileの閉じ括弧
}
/* ↓に関数定義している */
/**
* 引数に渡したデータをスプレッドシートに書き出す関数
*
* @param {Object[]} メインスクリプトで作成したdata
* Objectの形式
* [{"syamei": hoge, "syokusyu": hogehoge},
* {"syamei": hoge2, "syokusyu": hogehoge2}]
*
* @return {} なし
*/
function output_Spreadsheet(data){
// シートの取得(コンテナバインド前提)
var sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName("シート1")
// シートの使用している最終行を取得
var lastRowNum = sheet.getLastRow()
// 順番に書き出し
for(var i=0; i<data.length; i++){
sheet.getRange(lastRowNum+1+i,1).setValue(data[i].syamei)
sheet.getRange(lastRowNum+1+i,2).setValue(data[i].syokusyu)
}
}
まずは、次の部分で繰り返し処理を入れています。
// 次へボタンがある間は繰り返し
var tugie = true
while(tugie==true){
********* 省略 **********
}while(条件)で条件が満たされている間は繰り返す処理になります。
ここで言うと、変数tugieがtrueの間は繰り返す処理となっています。
分からない方は、次の記事を参考にしてください。
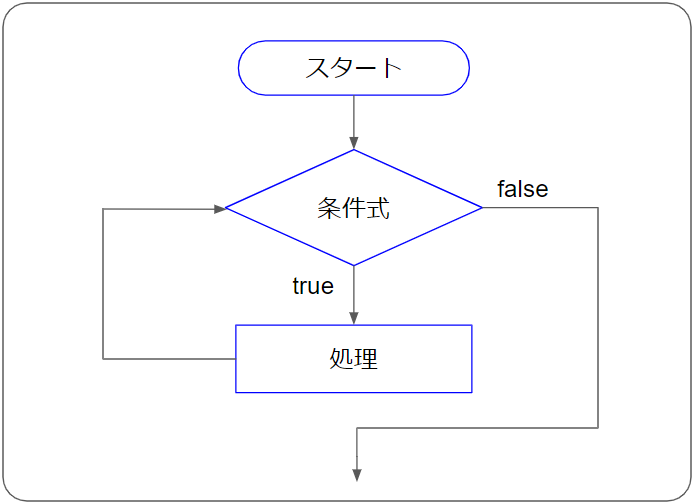
そして次の部分で、「次へ」ボタンの存在確認と、あった場合・無かった場合の分岐処理を行っています。
/* ここに次へボタンの処理を入れ込んでいる */
// 次へボタンがあるかどうか確認(ある場合は、変数urlを更新、無い場合は変数tugiheをfalseにする)
if(html.match(/次へ/)){
var tmp = parser.from('<li class="next">').to('</li>').build()
var p_next = Parser.data(tmp)
tmp = p_next.from('page').to(',').build()
url = "https://www.baitoru.com/kansai/jlist/hyogo/kobeshiigai/kakogun/" + "page" + tmp + "/"
}else{
tugie=false
}
/* ここまで */「html.match(/次へ/)」は、Stringオブジェクトのmatchメソッドを使って、htmlの中に「次へ」という文字列があるかどうかを判定しています。ある場合はtrue、無い場合はfalseが返ります。
Stringオブジェクト.match(/hoge/)
hogeの部分に入れた文字列があるかどうかを判別出来ます。
ない場合は、変数tugieをfalseに設定するので、次のループを抜けます。
ある場合は、以下です。
var tmp = parser.from('<li class="next">').to('</li>').build()
var p_next = Parser.data(tmp)
tmp = p_next.from('page').to(',').build()
url = "https://www.baitoru.com/kansai/jlist/hyogo/kobeshiigai/kakogun/" + "page" + tmp + "/"「次へ」があった場合、次のページのHTMLの情報を取ってくるためには、次のページのURLを
var html = UrlFetchApp.fetch(url).getContentText()
ここの変数url入れてやる必要があります。
HTMLの中にそのまま入れられるURLがあれば、それを取ってこれば良いのですが、このサイトの場合そういうようにはなってないみたいですね。。。
<li class="next">
<a href="javascript:void(0);" rel="nofollow" redirectlink=",kansai,jlist,hyogo,kobeshiigai,kakogun,page2,">次へ</a>
</li>一旦、ブラウザ上で自力で次へボタンを押してみて、次のページがどんなURLになっているのか確認しましょう。
すると、「次へ」を押すたびに、次のようにURLが変わっていることが分かります。




URLの最後に、「/page*/」が付いてるみたいですね。
これは使えそうです(^o^)
次へボタンは、<li class=”next”>~</li>で絞り込めそうですし。一番最後に「page*」という感じで、次のページが何ページかも分かります。
// 一旦ざっくり絞り込む
var tmp = parser.from('<li class="next">').to('</li>').build()
var p_next = Parser.data(tmp)
// 絞り込んだもので、「page」と「,」の間の数字を取る
tmp = p_next.from('page').to(',').build()
// url組み合わせる
url = "https://www.baitoru.com/kansai/jlist/hyogo/kobeshiigai/kakogun/" + "page" + tmp + "/"これで次のページのurlを作ることが出来ました。
では実行してみましょう。
次へのページ進んで、該当データの取得が出来ました!
まとめ
「WEBサイトの情報をGASで取得する2」でした。次のページのURLの取得方法や、そもそもそれが最後のページなのかを判断する方法は、サイトの構造によって変わってきますし、一つのサイトでも1通りとは限りません。
今回は、この方法で実装しましたが、もしかしたらもっとコードを簡単にする方法もあるかもしれませんので、ターゲットのサイトのソースをよーく眺めて、どんな構造になっているのか考えてみてください!
注意点
やり方によっては、ターゲットのサイトのサーバーに負荷を掛けすぎてしまう場合があります。1回のリクエストの間隔は1秒以上空けるなど、相手に迷惑がかからないように注意してください。
その他、そもそもGASのプログラムの実行は6分間という制限もあります。ページ数が多かったり、処理が複雑になると6分間では終わらない場合もあるかと思います。そういった場合、別の対処が必要です。
などなど、問題が起きた場合の責任は取れませんので、全てのことは自己責任で宜しくお願いいたします。
コメント